合合信息文字识别训练平台:内置五大算法模型,零门槛开发全版式文档信息抽取模型
当前,OCR已在各行各业的信息录入、审核、电子化、归档管理等场景中得到了普遍应用。企业对信息抽取的精度、版式覆盖全面性、迭代速度与灵活度等也随之有了更高的要求。尤其是对于业务流程中需要处理大量种类繁多的定制文档、不固定版式单证的企业而言,范围有限的常规证件、发票的信息识别与抽取模型已经无法满足业务需求。
越来越多的企业开始尝试采用自主研发或定制开发文档信息抽取模型的方式,以满足个性化的文档识别需求。但是,自主研发需要从零起步组建团队,人力成本高,需要攻克大量技术难题,模型可用性难以保证;定制开发模型则面临着“一种版式对应一个模型”导致定制成本高、驻场开发定制周期长、无法自主迭代、泛化能力差、易重复采购、业务数据保密性要求高等诸多困难。
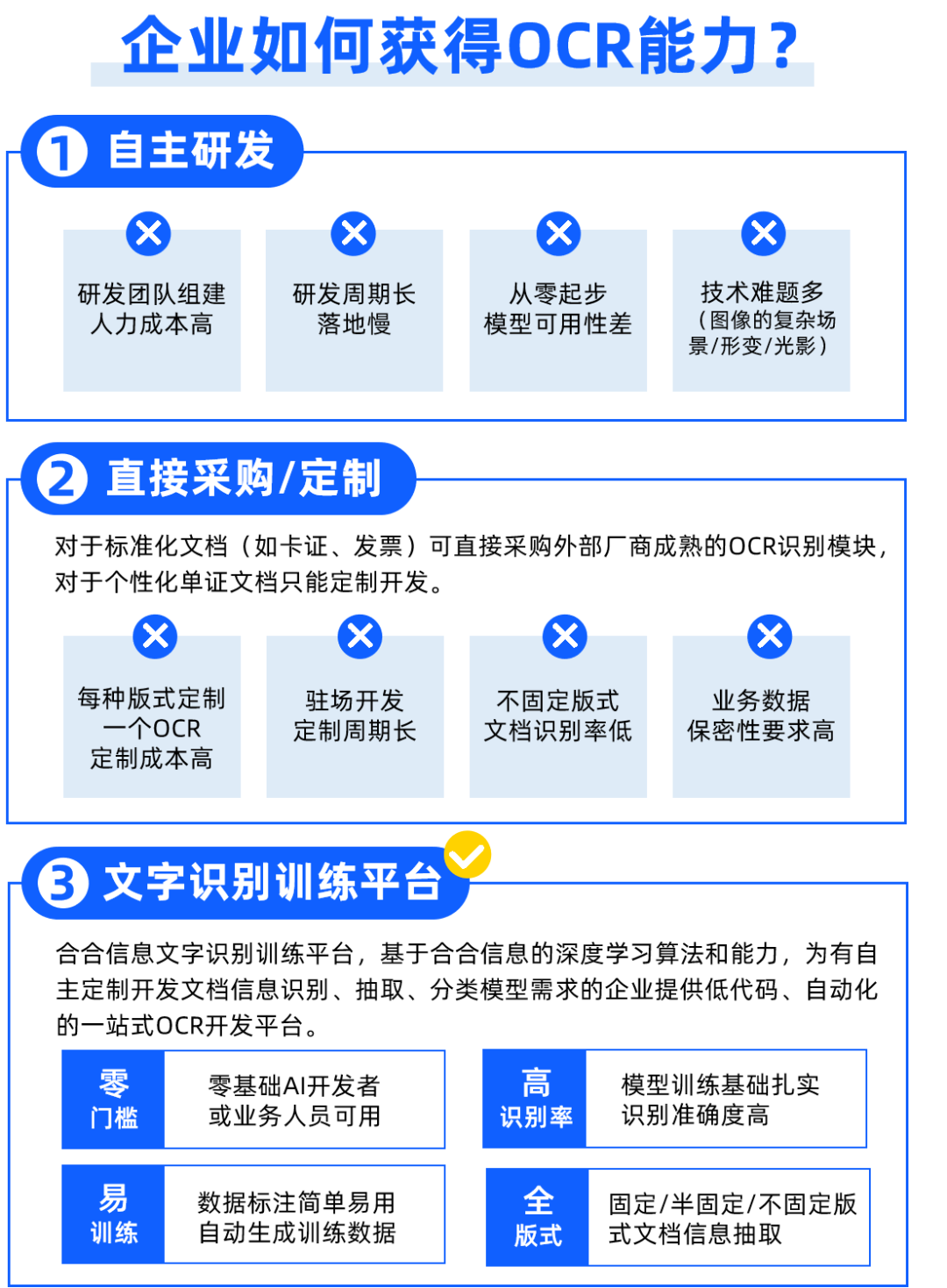
为了解决上述痛点,合合信息推出文字识别训练平台,基于合合信息的深度学习算法和能力,为有自主定制开发文档信息识别、抽取、分类模型需求的企业提供低代码、自动化的一站式OCR开发平台。零算法基础开发者与实际业务人员,通过简单操作即可自主完成模型训练开发全流程。

合合信息文字识别训练平台是面向零基础的开发者或实际业务人员的全流程一站式OCR开发平台。针对文本检测、文字识别、文档分类、信息抽取等任务,基于先进的深度学习算法,提供了集模型创建、数据标注、模型训练、模型测试、模型部署于一体的机器学习服务。
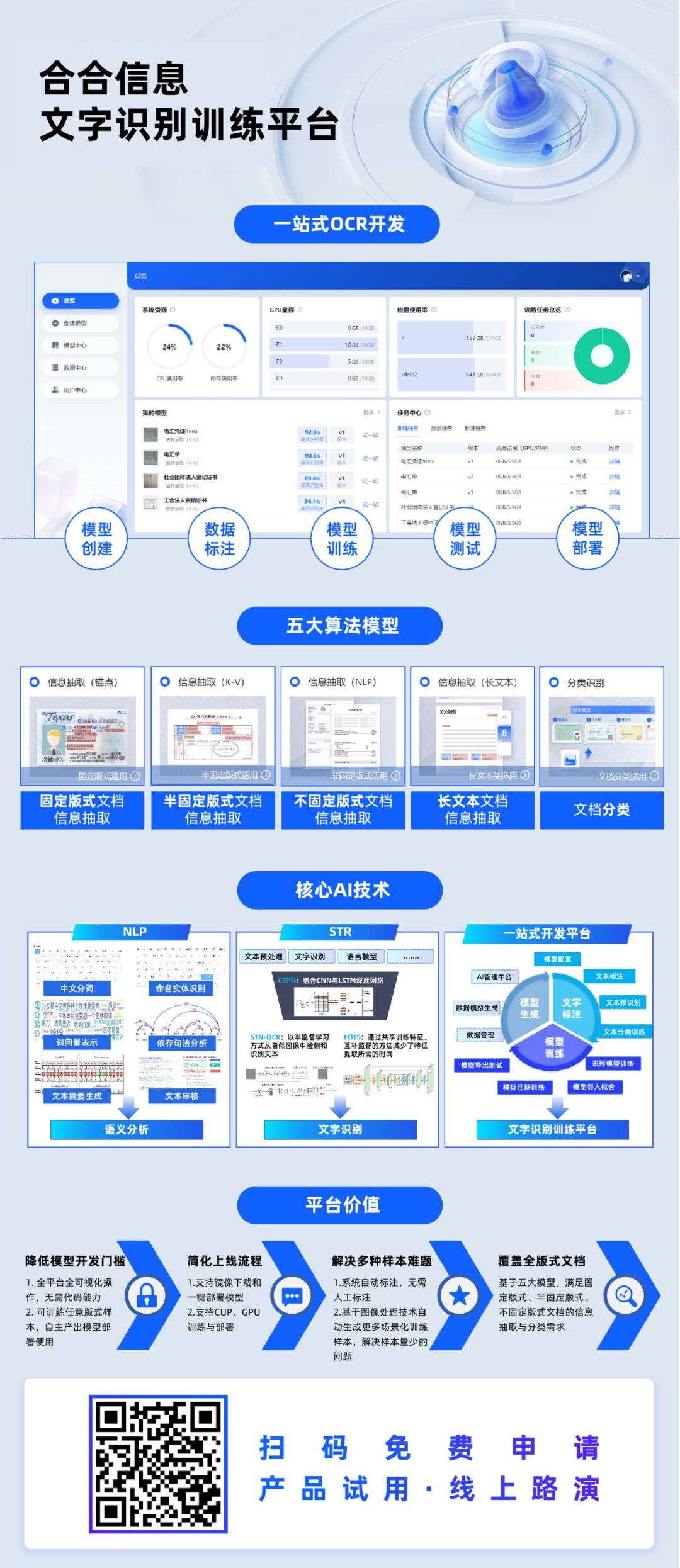
合合信息文字识别训练平台内置了场景丰富的算法模型,配备了信息抽取(锚点)、信息抽取(K-V)、信息抽取(NLP)、信息抽取(长文本)、分类识别五大模型类型,以满足固定版式、半固定版式、不固定版式的单页与多页文档的信息抽取与分类需求,根据文档特点创建适配的模型类型,有效提升识别精度,降低模型训练难度。

1.信息抽取(锚点)
基于预置的文字检测与识别模型,针对固定版式的卡证票据,框选出版式参照区与所需提取的信息区域,即可实现数据的结构化提取。选择该模型无需训练,只需要一张标注样本即可直接创建模型。
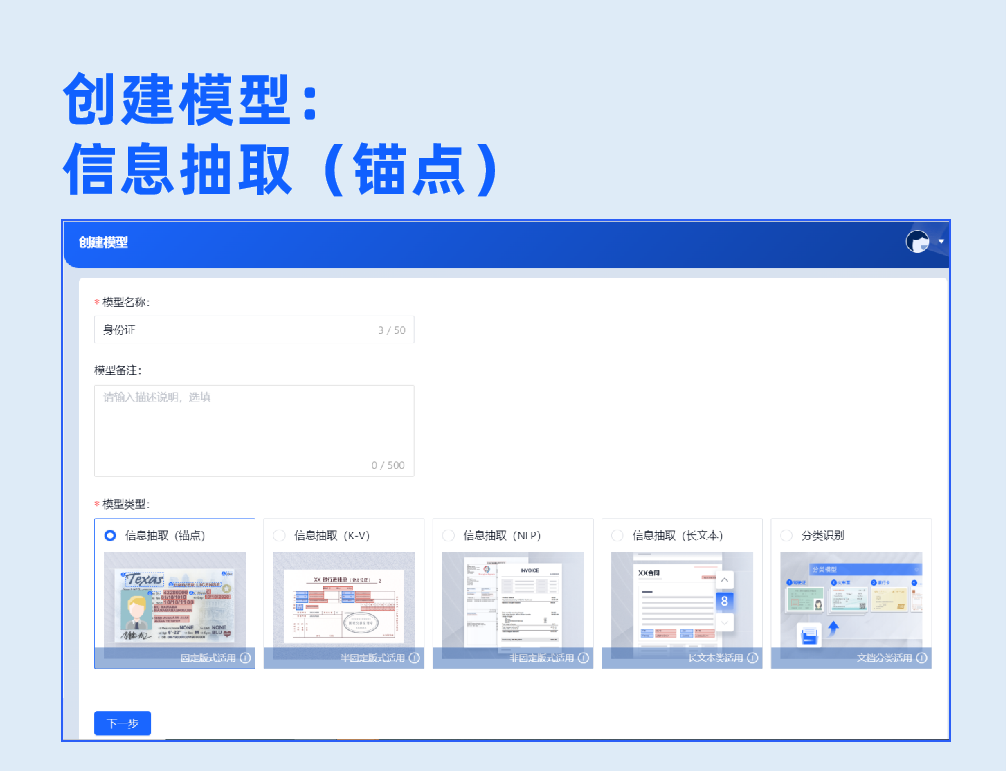
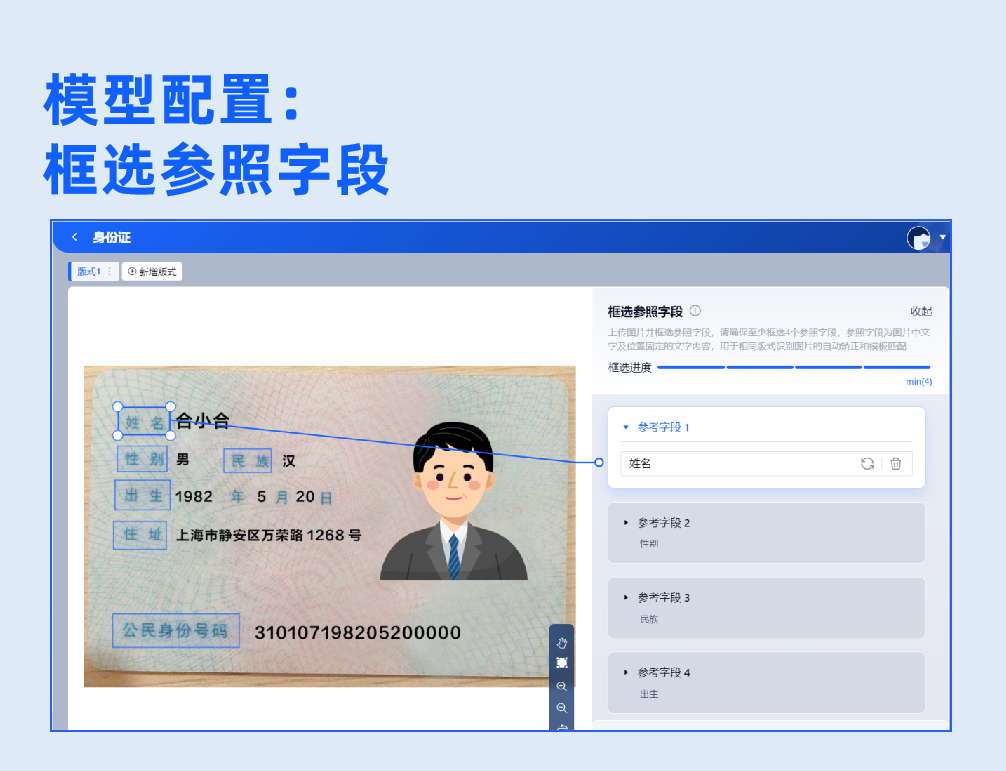
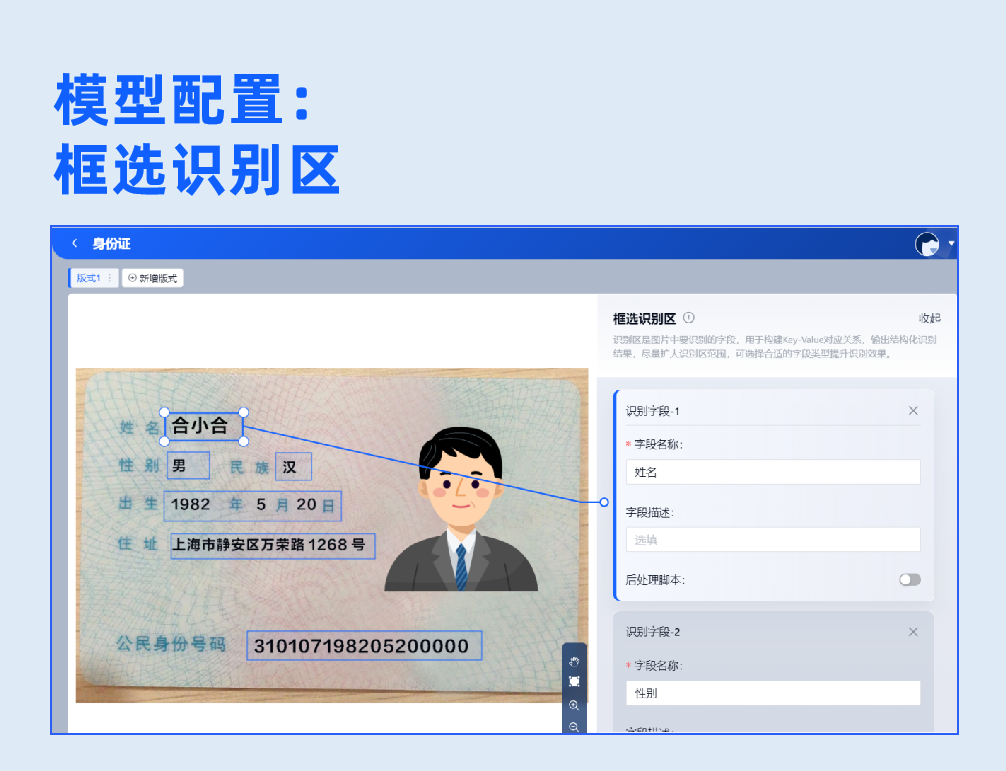
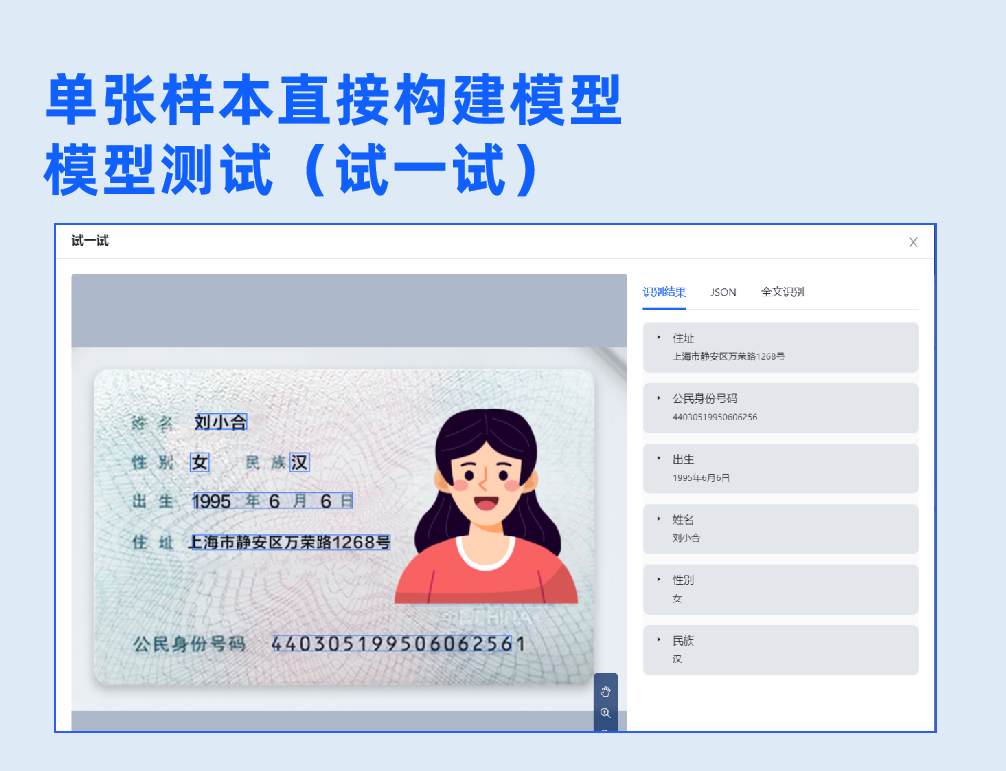
左滑查看信息抽取(锚点)模型开发过程>>
2.信息抽取(K-V)
基于内置的高性能预训练模型,针对用户标注的键值对位置和文本信息,训练专属场景的AI模型,从而提升文本检测、文本识别、字段属性分析的精度,此模型适用于半固定版式的文档分析,例如卡证、票据等。
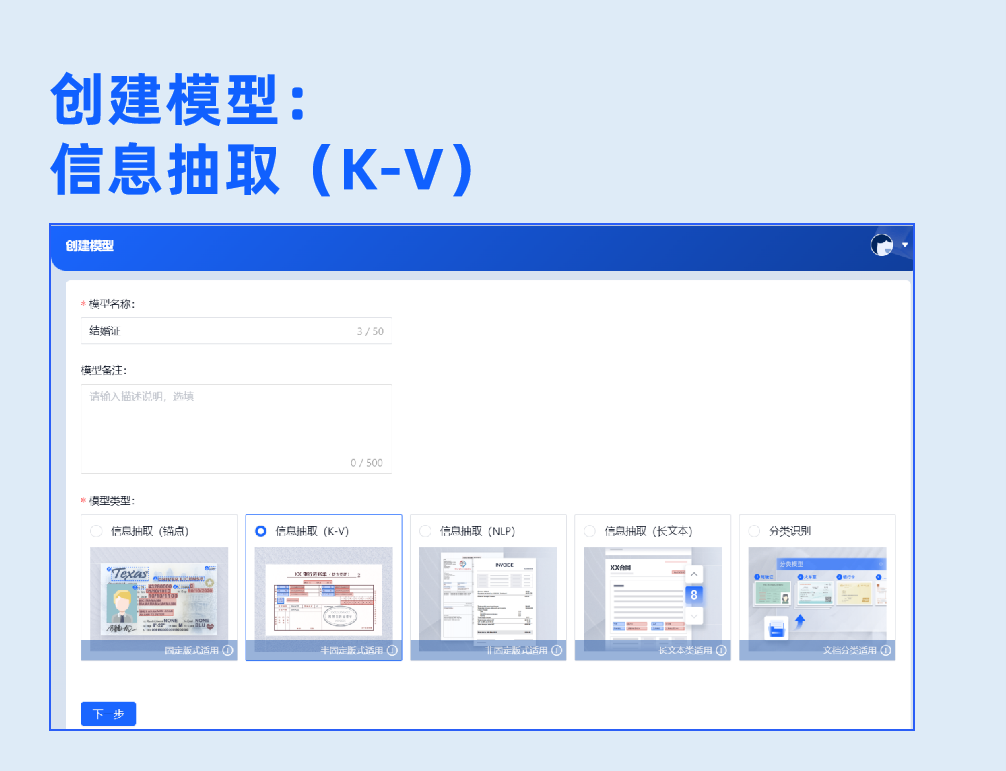
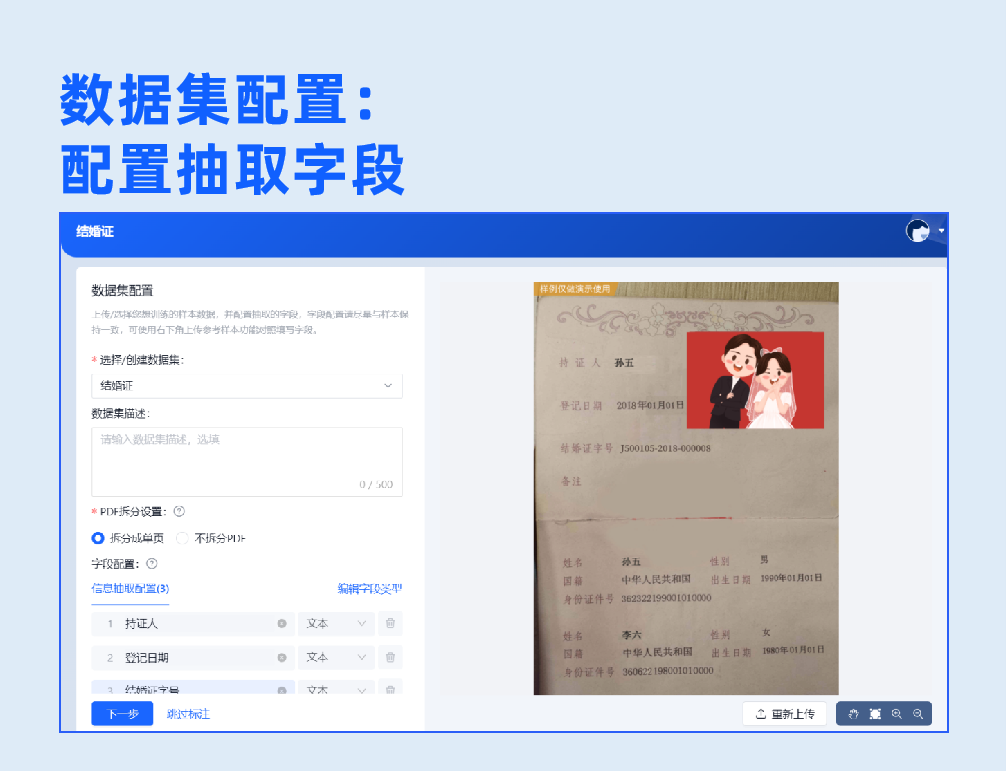
3.信息抽取(NLP)
基于内置的多模态(图像、文本)高性能预训练模型,针对用户标注的键值对位置和文本信息,训练专属场景的信息抽取模型,从而提升文本检测、文本识别、字段属性分析的精度,此模型适用于单页不固定版式的文档分析,例如海外Invoice、物流单据等。

左滑查看信息抽取(NLP)模型开发过程>>
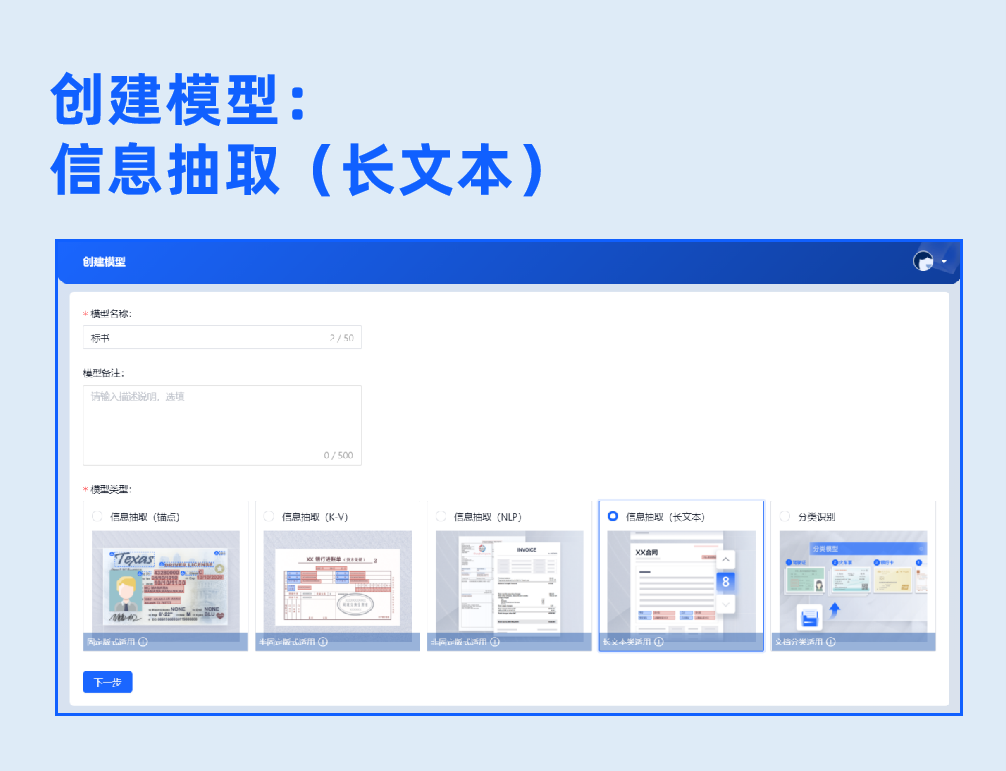
4.信息抽取(长文本)
基于内置的多模态(图像、文本)高性能预训练模型,针对用户标注的键值对位置和文本信息,训练专属场景的信息抽取模型,从而提升文本检测、文本识别、字段属性分析的精度,此模型适用于多页不固定版式的文档分析,例如合同、报告、标书、法律文书等。
信息抽取(NLP)与信息抽取(长文本)模型,基于自然语言处理技术,实现了“智能化语义理解”,可以很好地解决不固定版式文档中的文本空间位置不固定,导致模型抽取精度低、泛化能力差的问题。
5.分类识别
通过大量图片类型标注,基于深度学习算法学习图片特征,从而实现图片的分类识别。
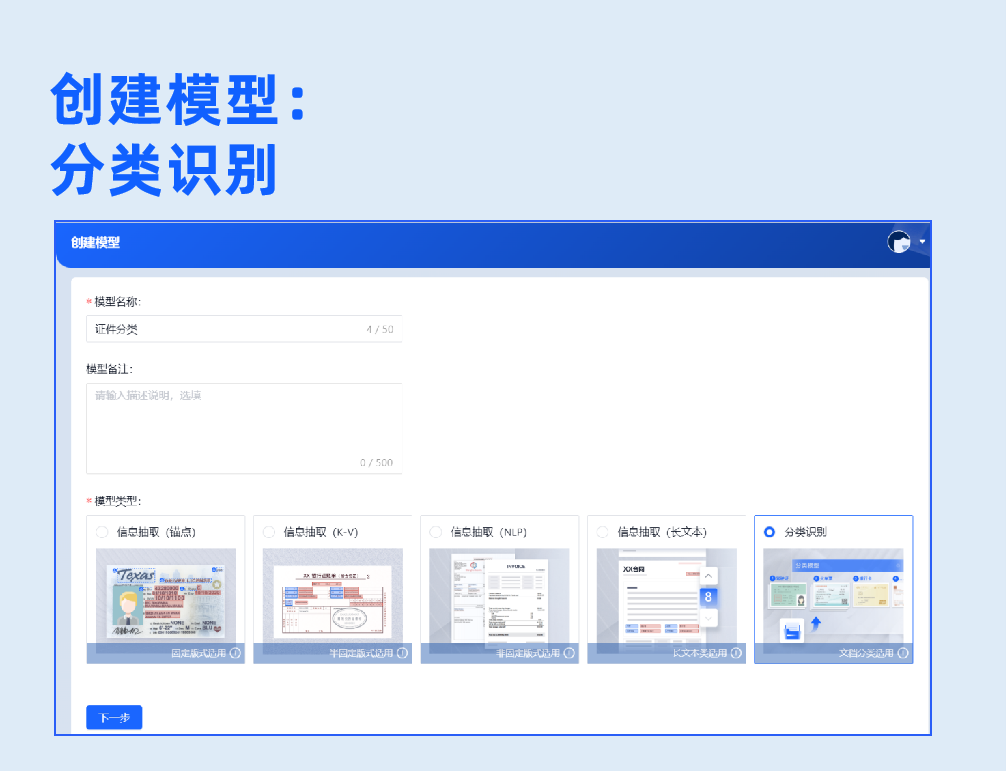
左滑查看分类识别模型开发过程>>

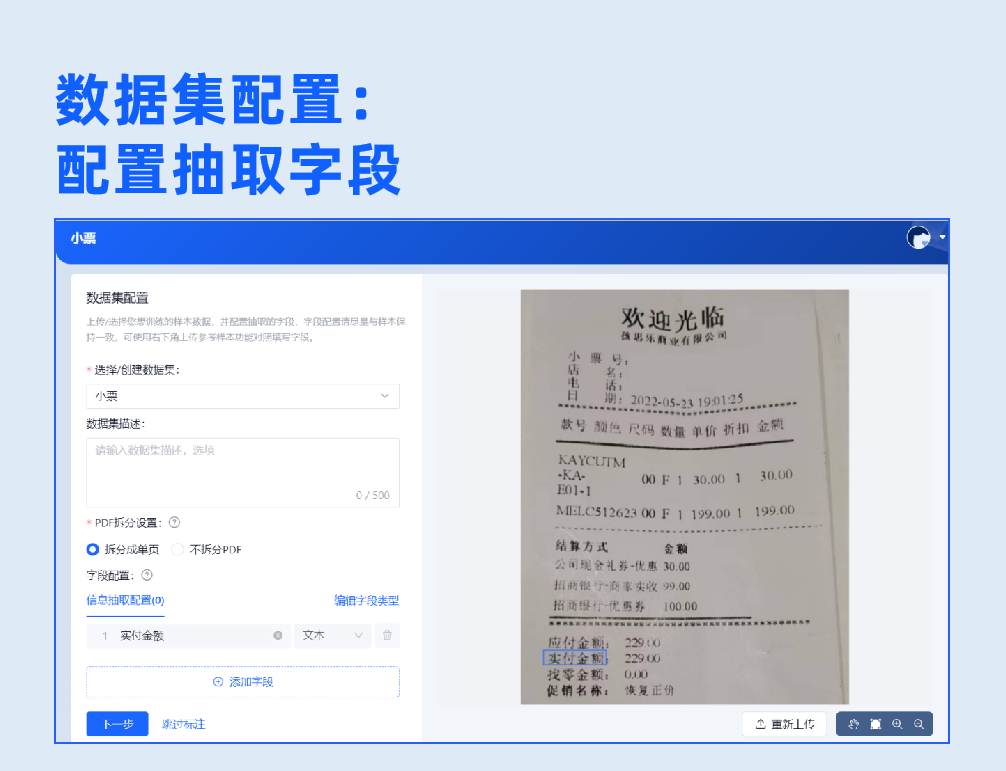
1.模型创建
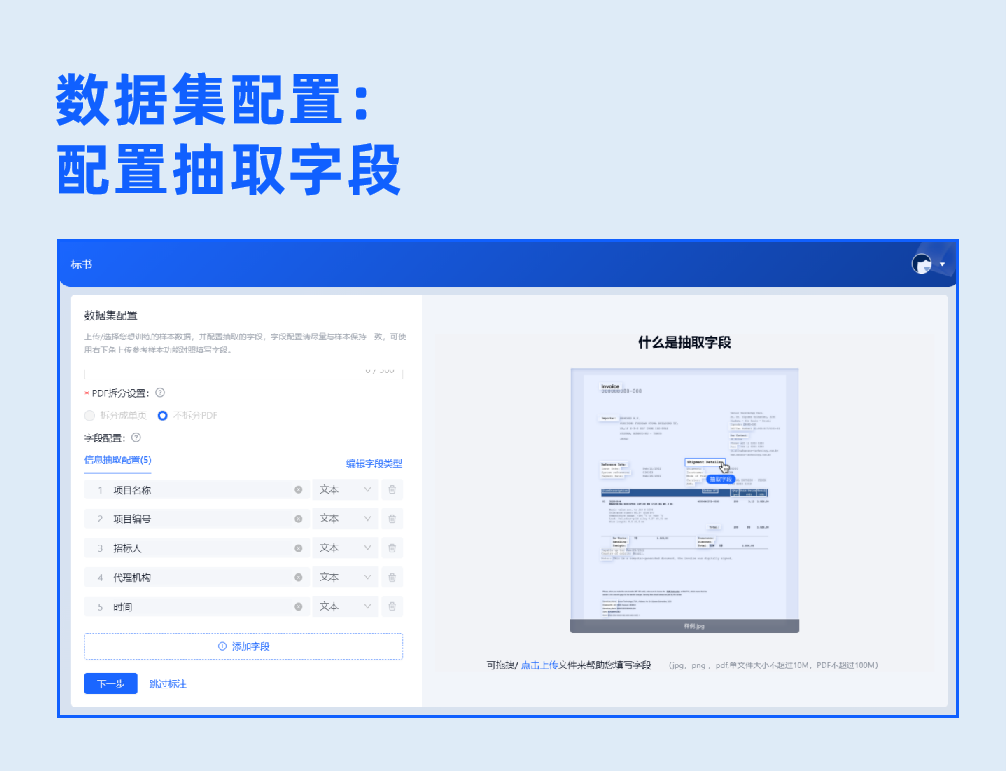
信息抽取(锚点)、信息抽取(K-V)、信息抽取(NLP)、信息抽取(长文本)、分类识别五大模型类型自主选择,满足不同版式文档的信息抽取与分类需求。全可视开发,配置操作简单,支持配置文本、印章、表格、手写文本、一维码、二维码等字段类型。
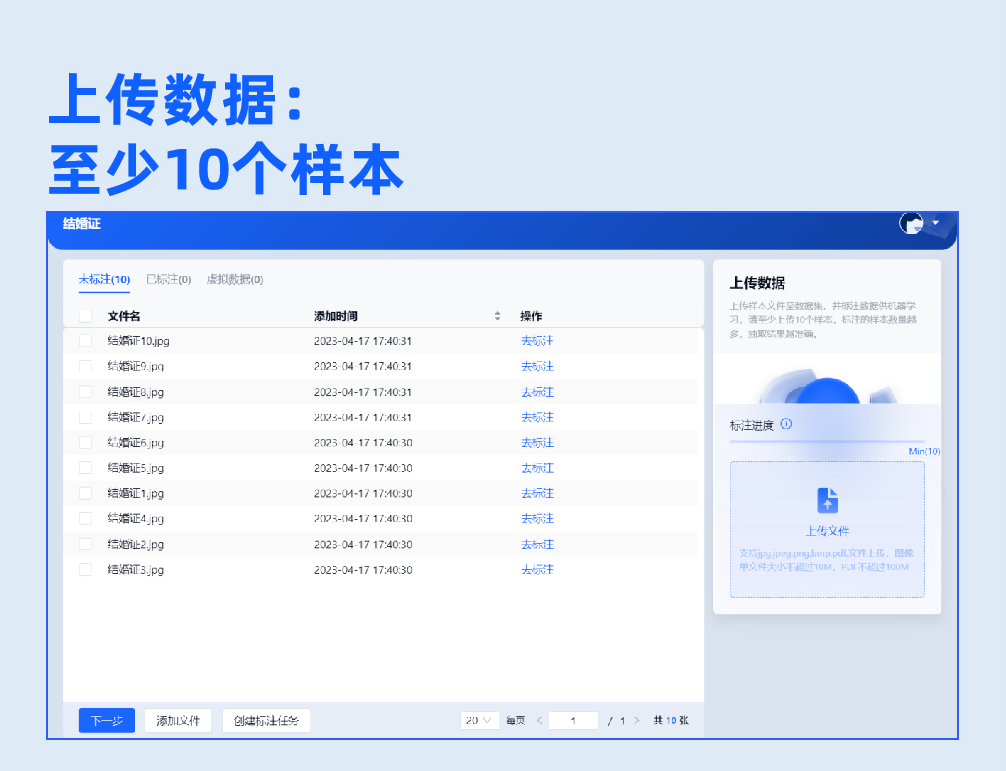
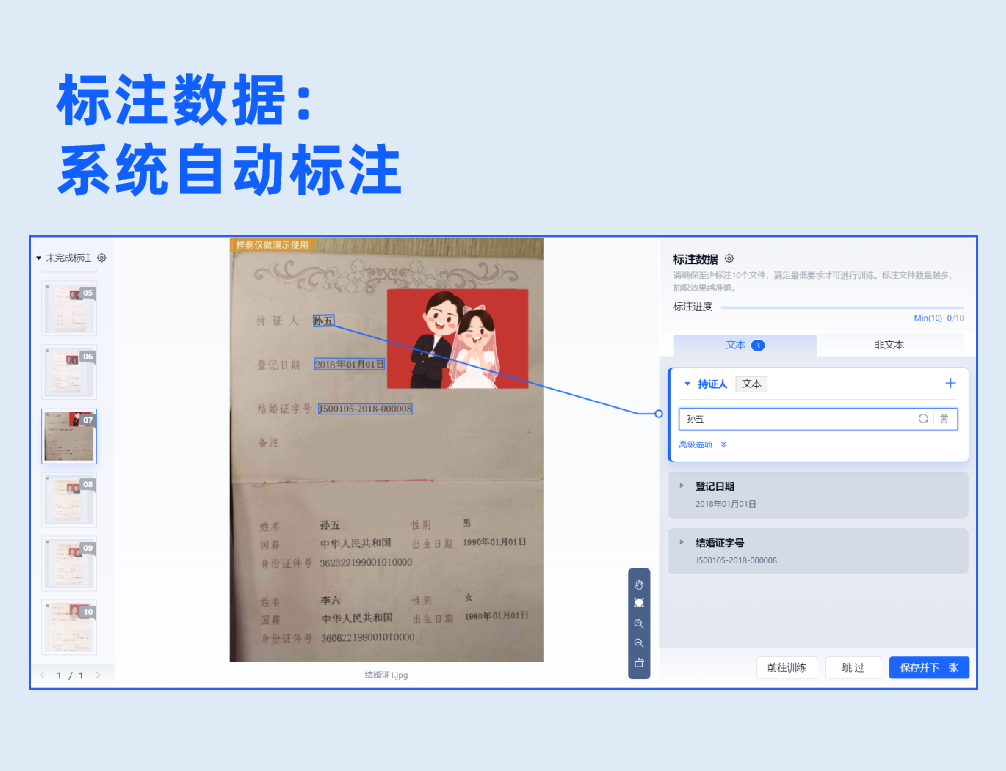
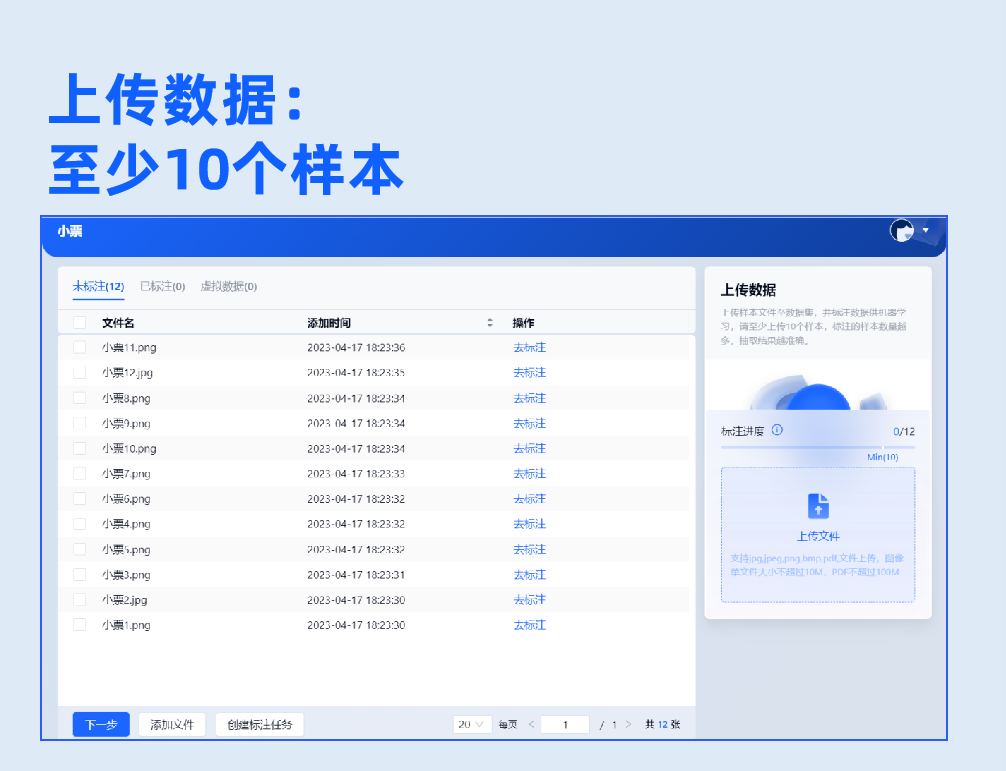
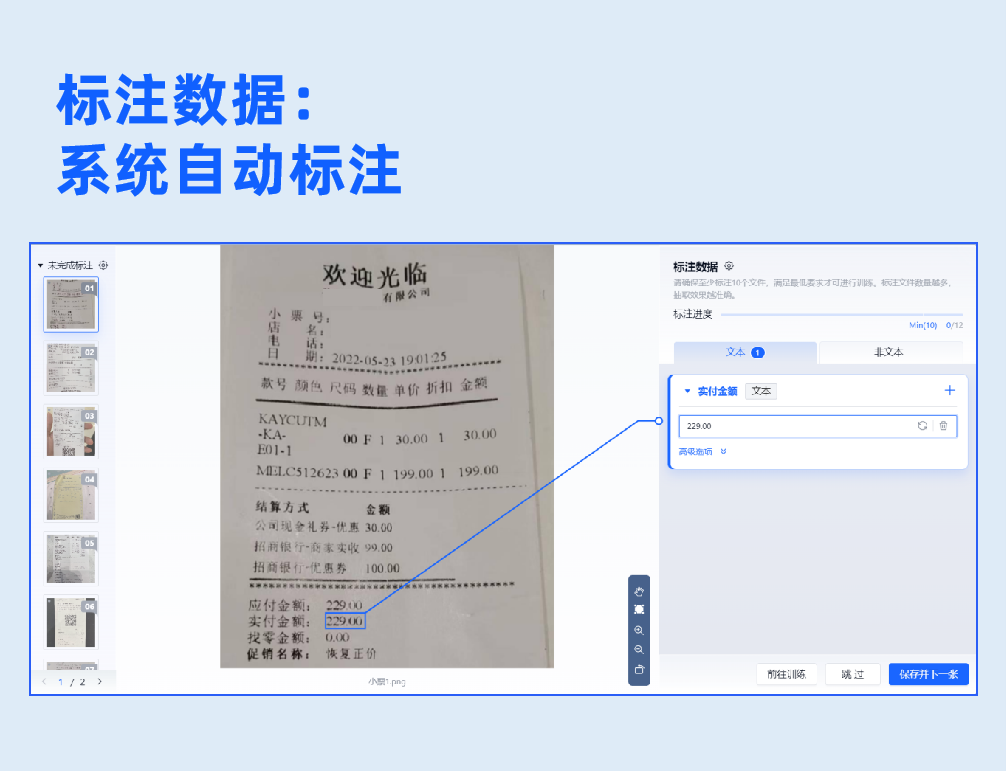
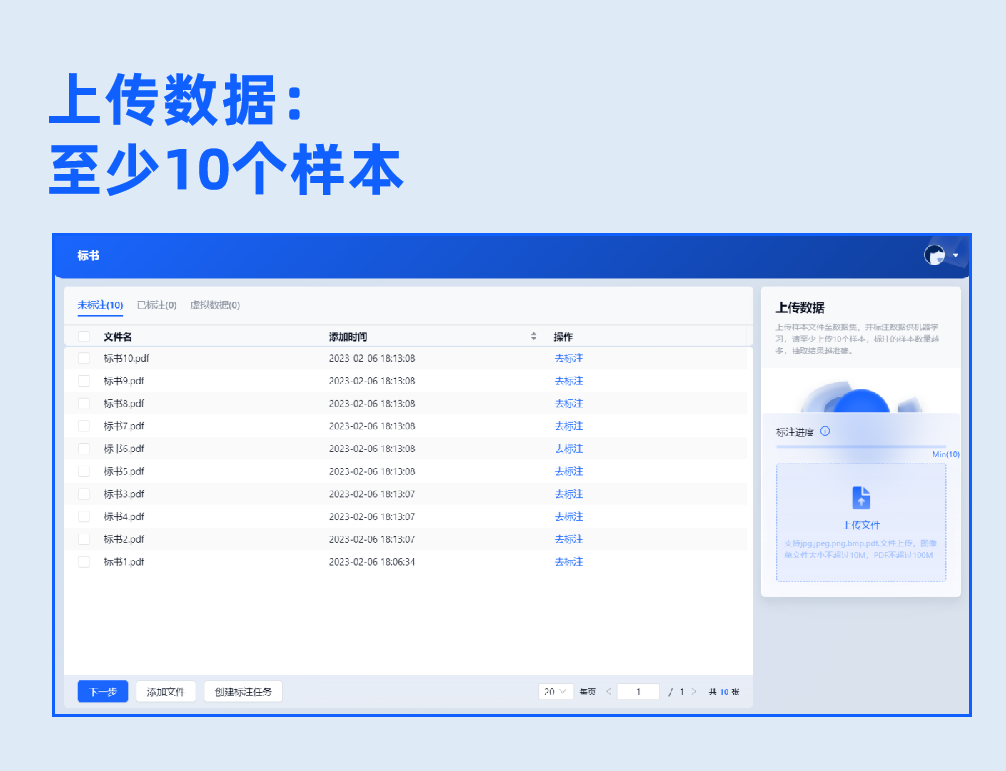
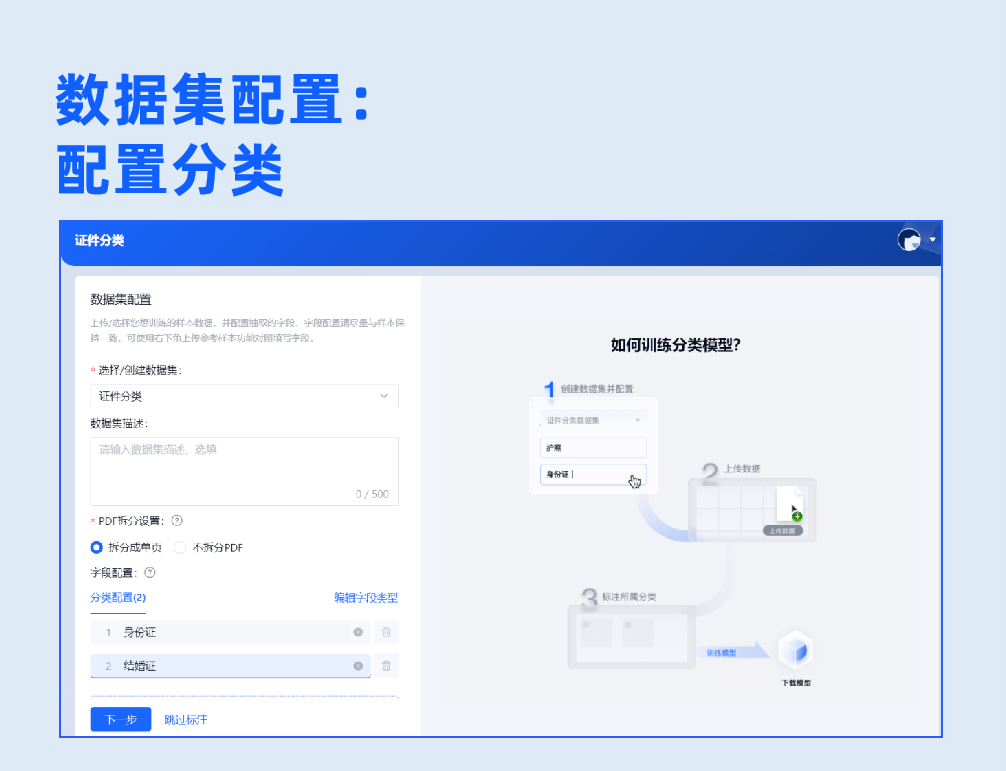
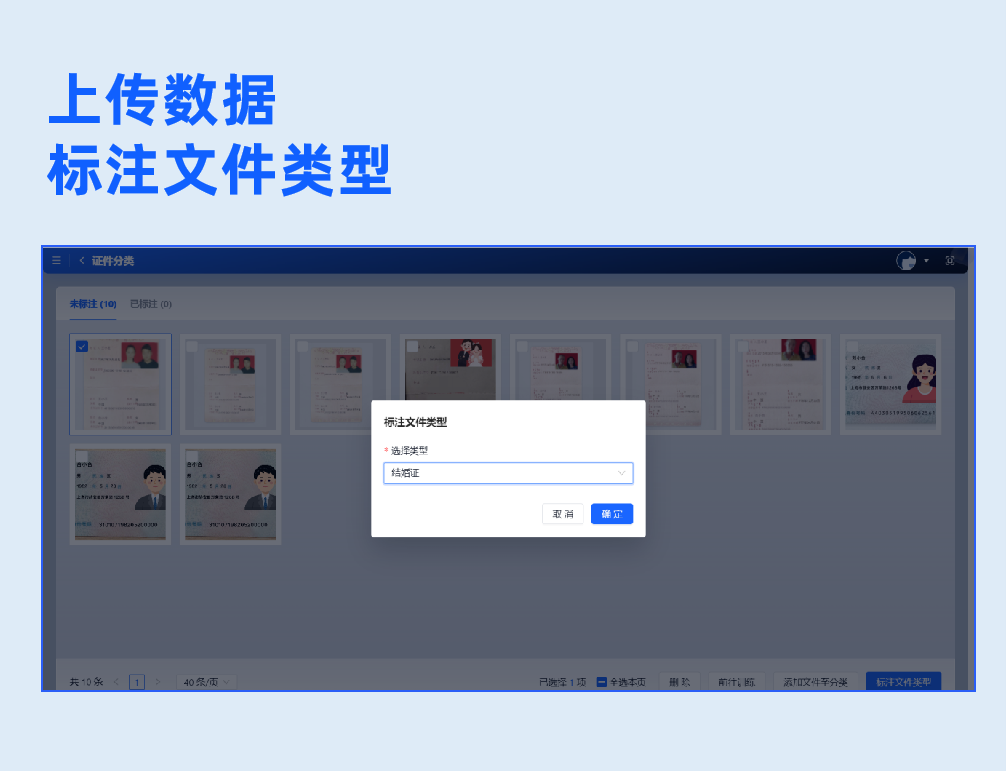
2.数据标注
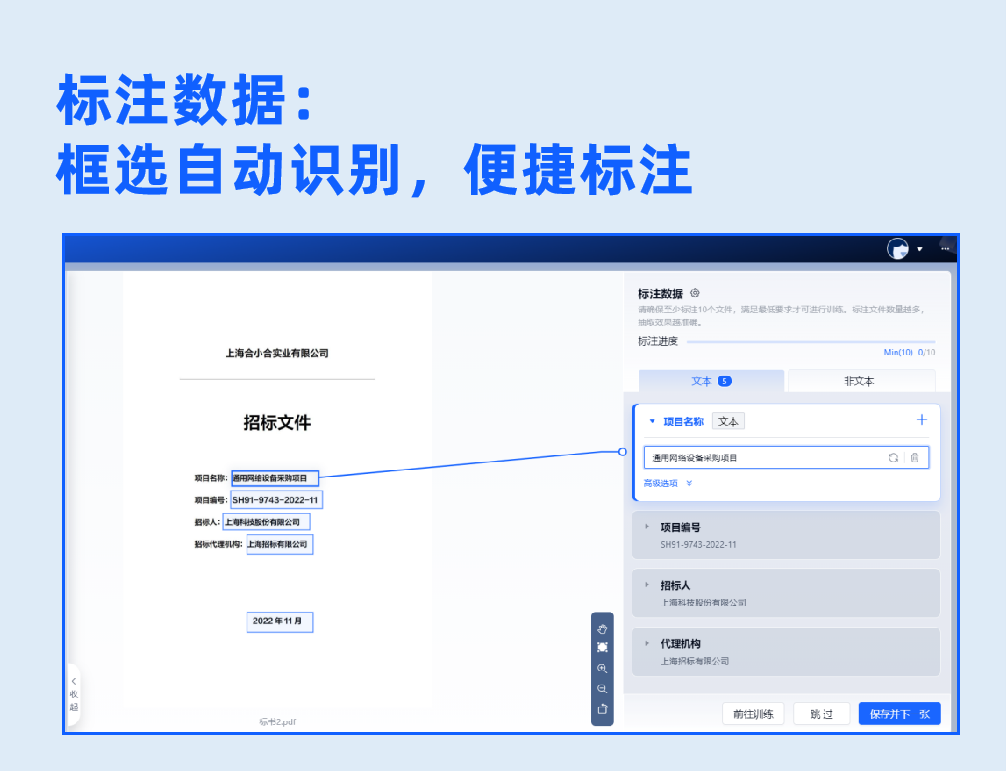
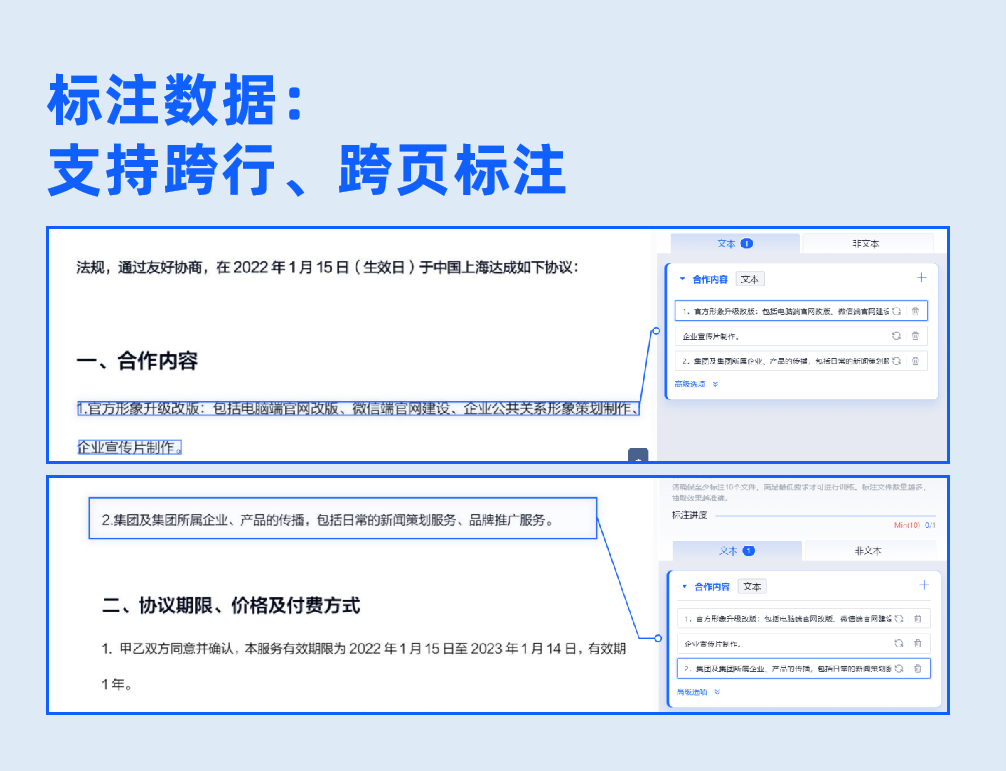
批量上传样本图片,支持生成虚拟数据。基于系统内置的NLP预标注模型,实现自动预标注数据,无需人工标注,系统自动根据配置字段进行信息抽取,大幅度提升标注效率。用户只需复核抽取结果,即可生成标注良好的可用样本。
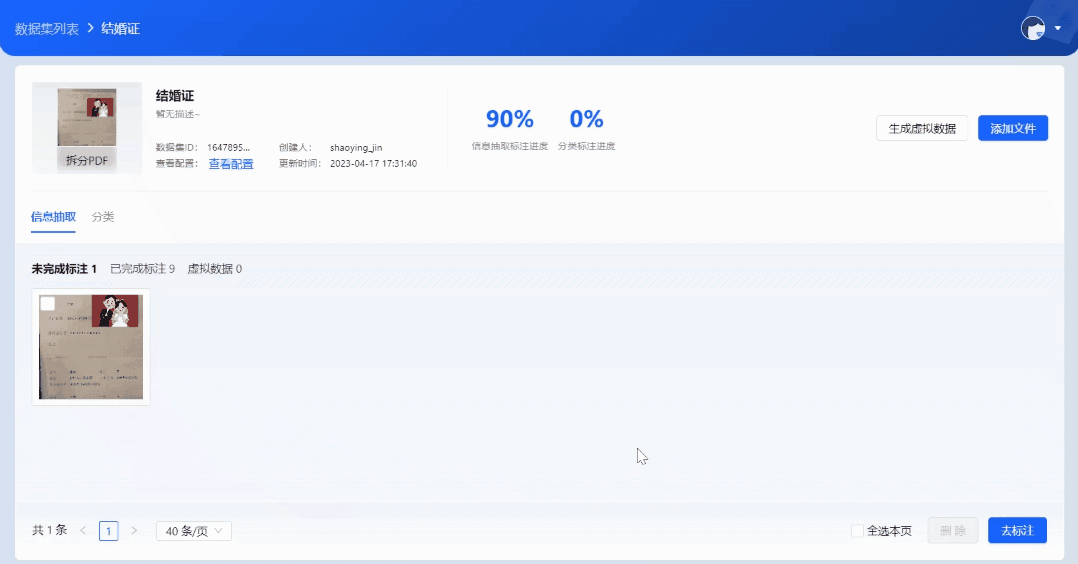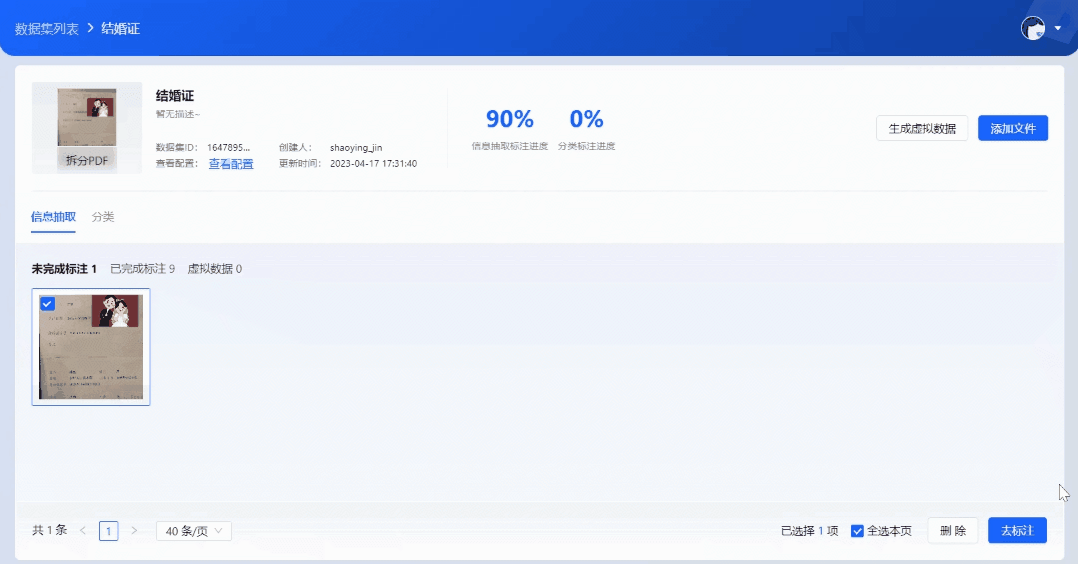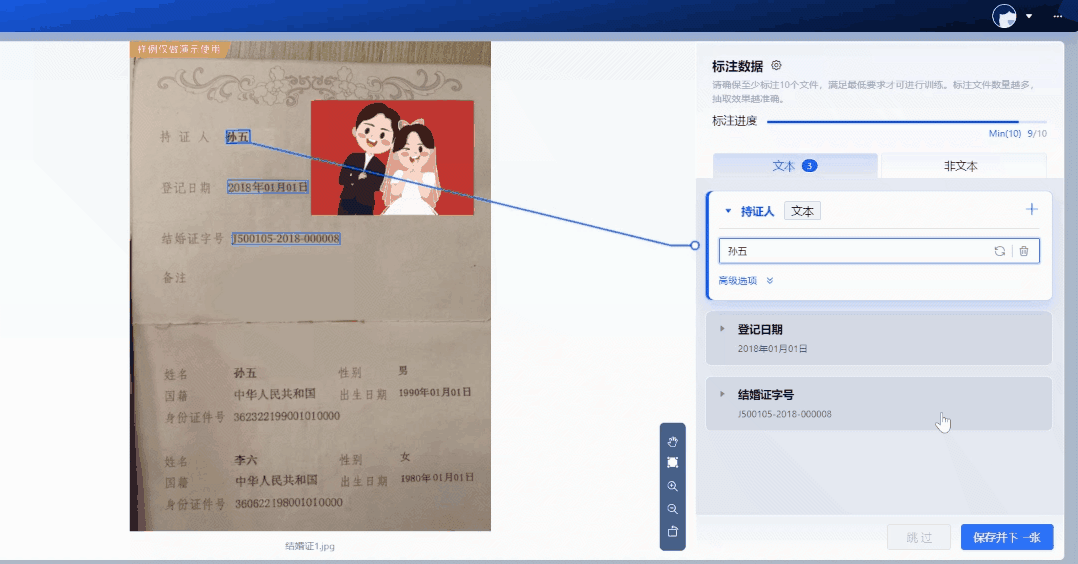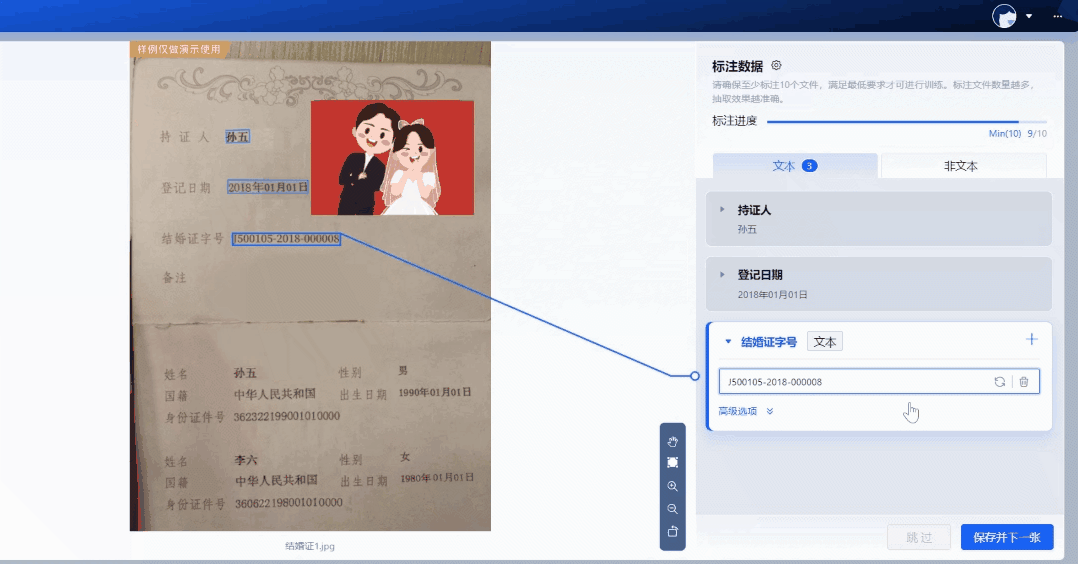
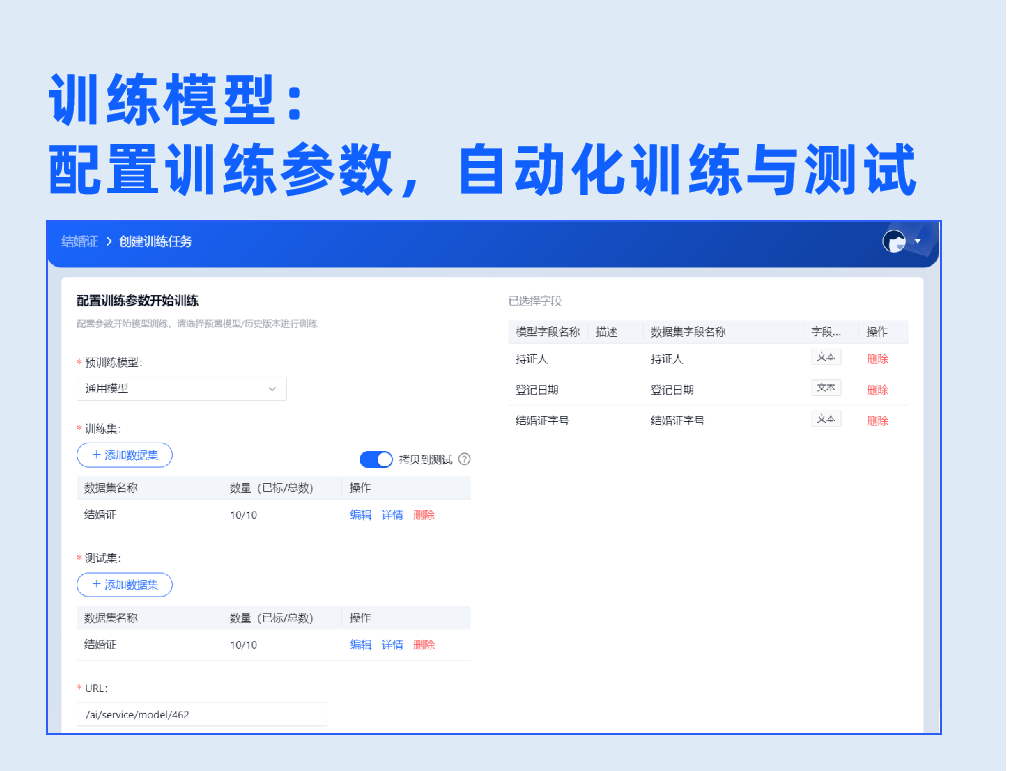
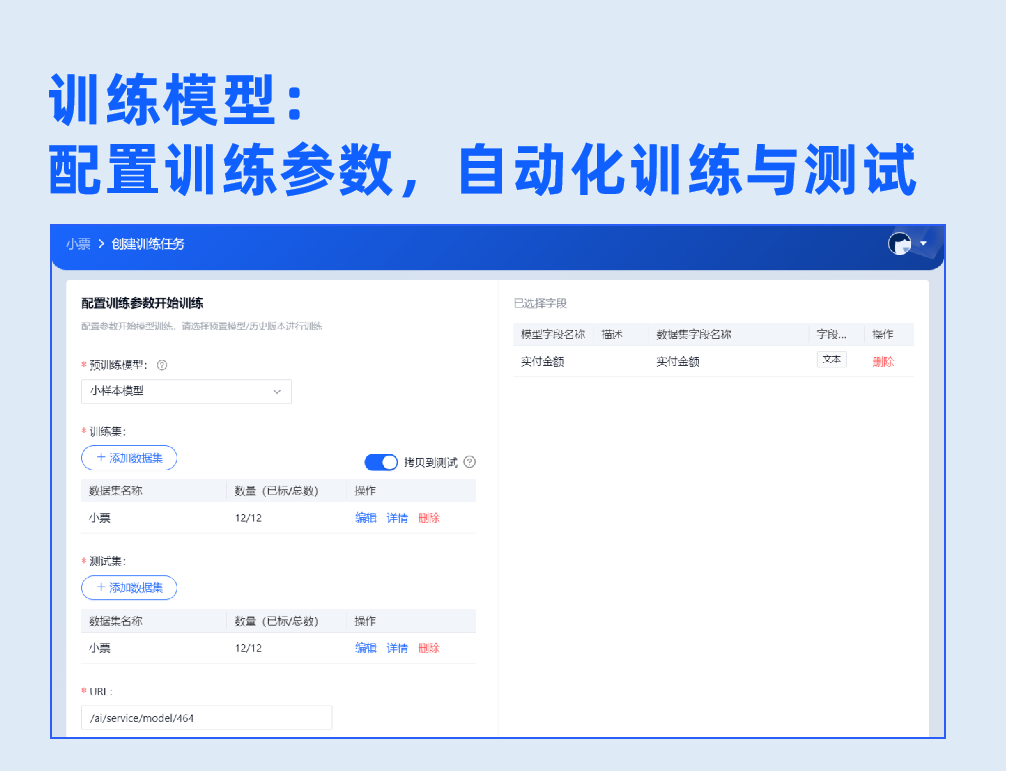
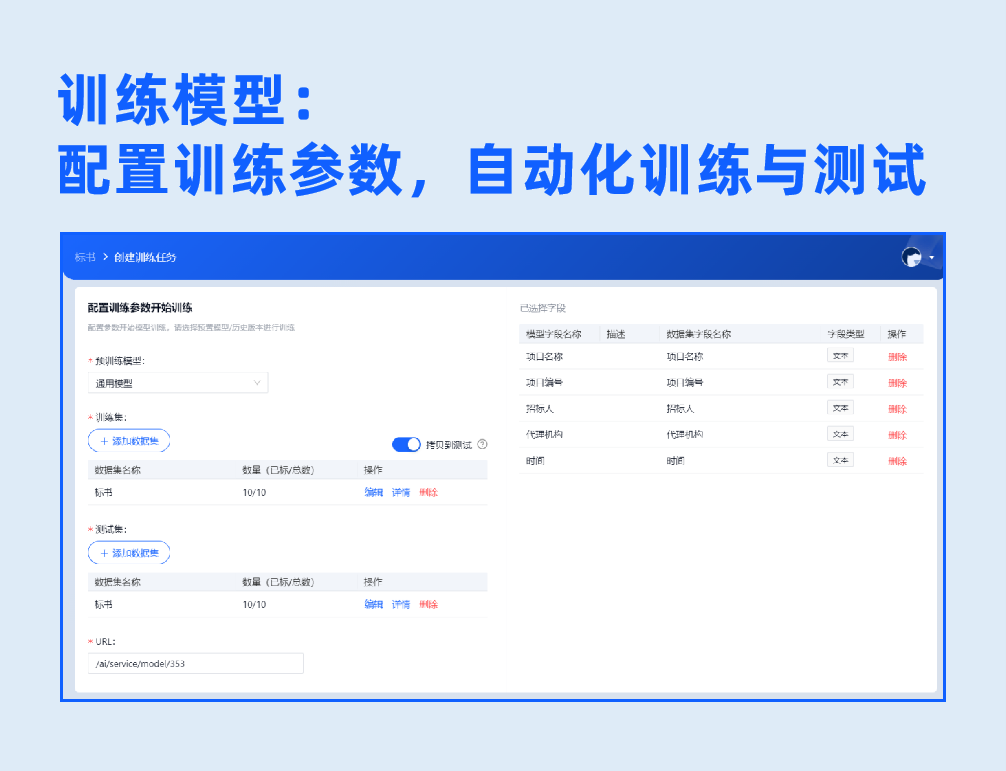
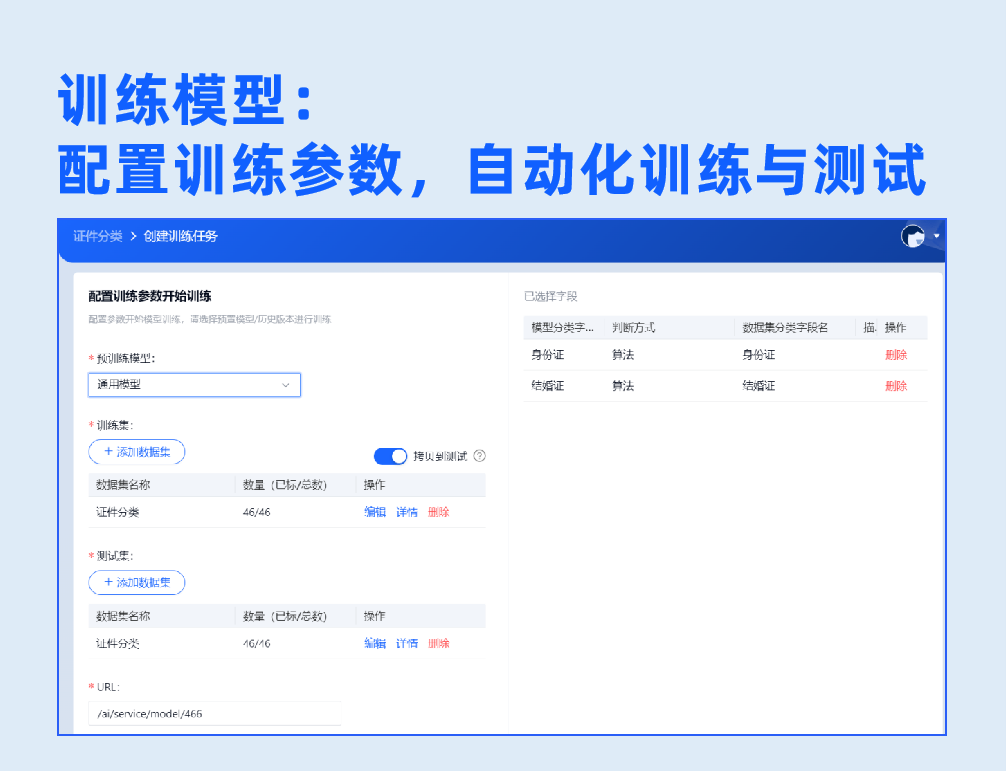
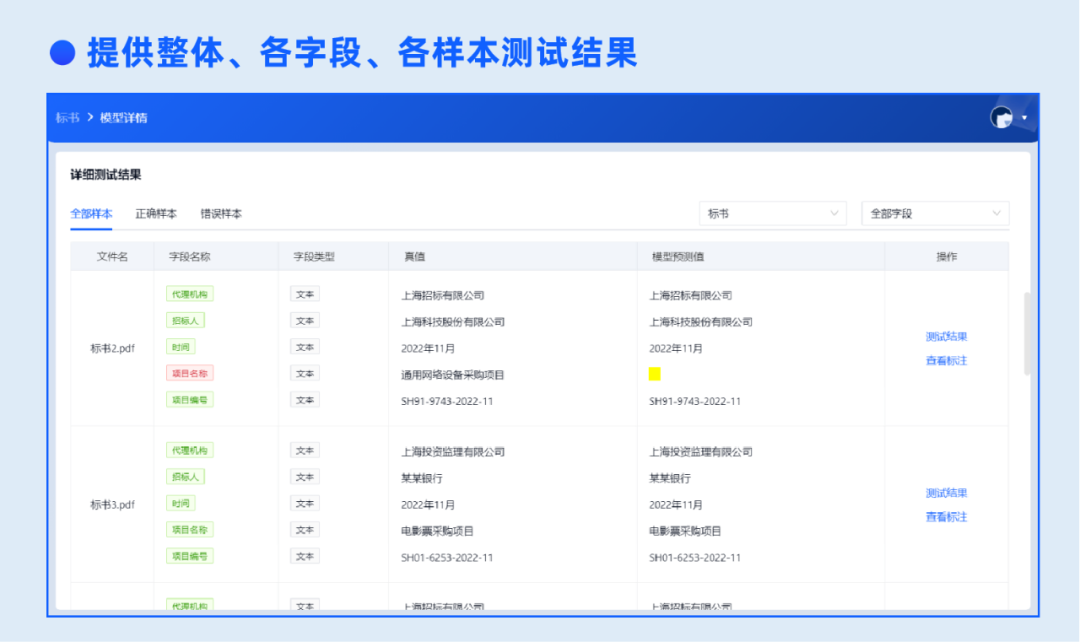
3.模型训练&测试
配置训练参数,一键开启自动化训练与测试,提供测试报告展示整体、每个字段识别率,以及每张样本的详细测试结果,模型识别率一目了然。
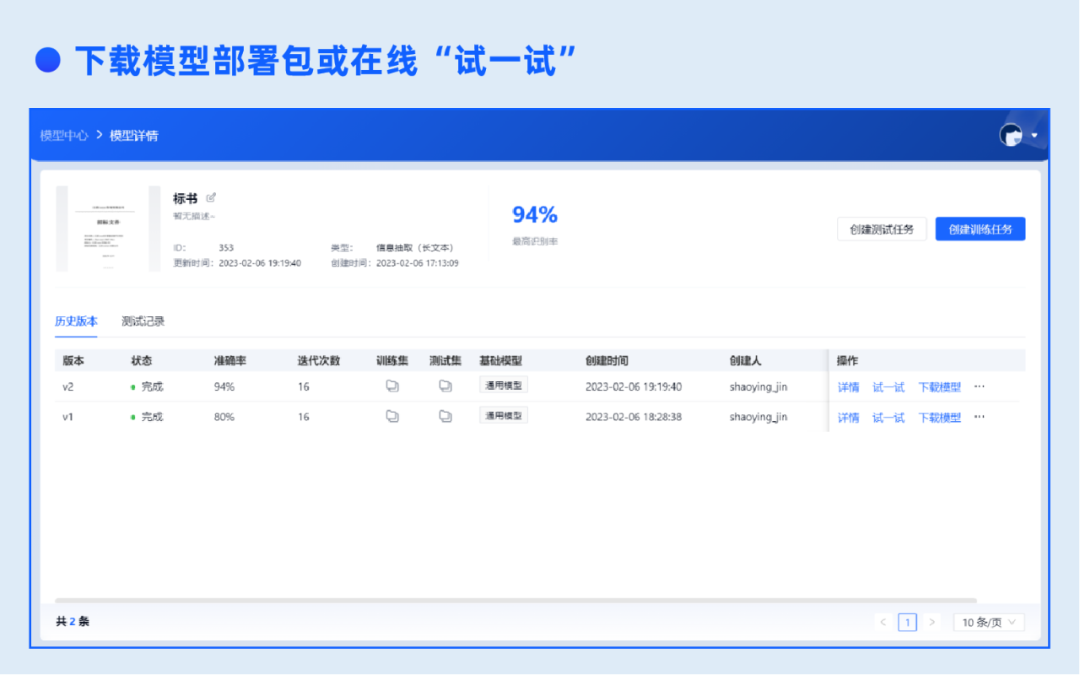
4.模型部署
下载模型部署包,部署到服务器,即可通过API调用。支持在线“试一试”。

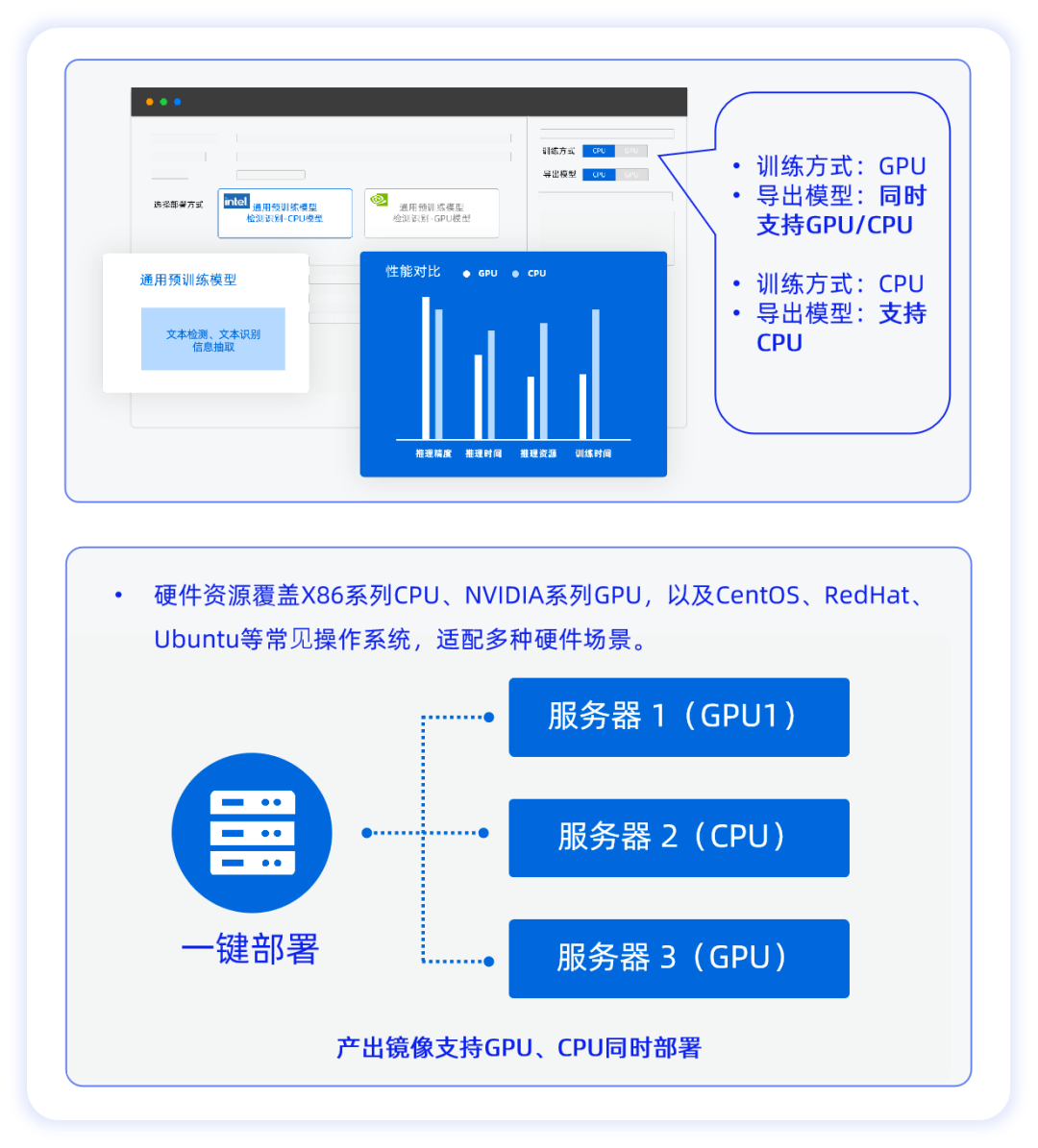
1. 支持CPU/GPU混合训练部署,单GPU和纯CPU训练部署
合合信息文字识别训练平台支持GPU/CPU混合训练、混合推理部署、多模块合并,支持单GPU和纯CPU训练部署。企业可以在现有的硬件基础上直接部署文字识别训练平台,不需要额外的硬件投入,可降低企业硬件改造成本,灵活性高,鲁棒性强。
2.数据回流,终身自主学习
合合信息文字识别训练平台具备数据回流功能,通过搭建数据回流交换平台连接业务平台(数据生产系统)与文字识别训练平台,将实际业务中产生的标注信息数据进行拉取、整合、统计后回流至文字识别训练平台,并用于对应模型的训练,提升模型的识别准确率,实现“在业务场景中越用越好用”的持续迭代效果,真正做到了智能化和终身自主学习。
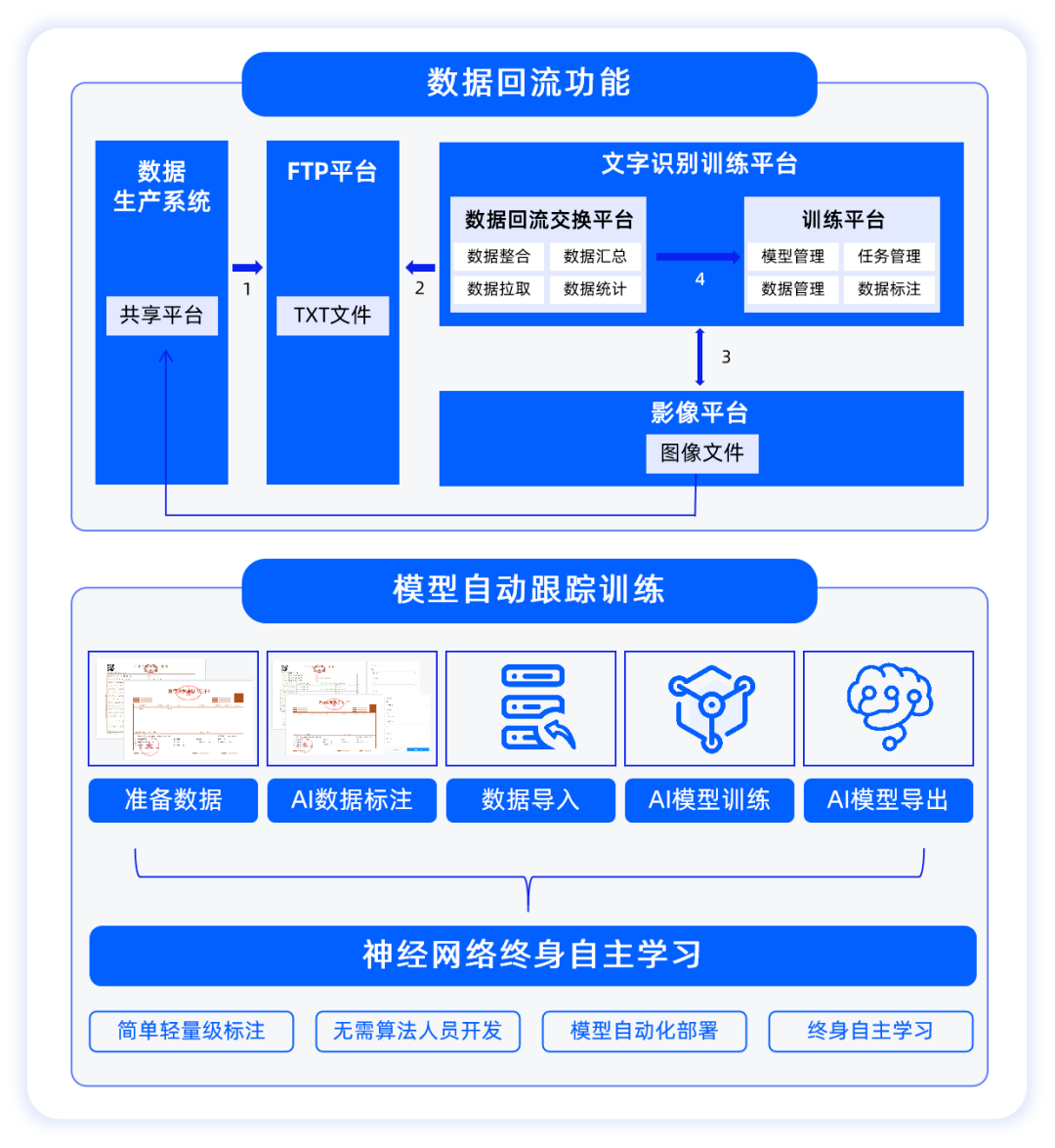
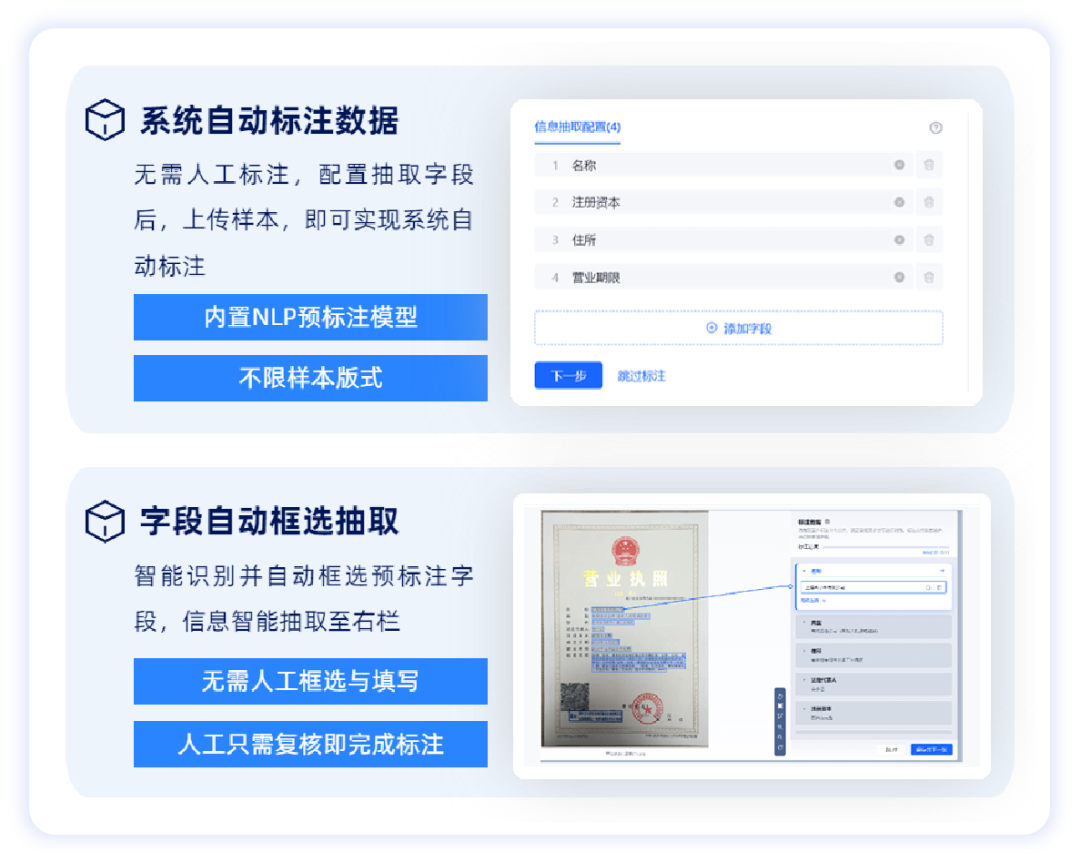
3.系统自动标注数据,无需人工标注
用户只需配置抽取字段,上传样本后,系统自动标注数据,人工只需进行复核即可,将传统的算法工程师“人工标注+人工复核”流程简化为“智能机器标注+人工复核”,零算法基础开发者与实际业务人员也可自主完成模型标注训练全流程,大幅度降低了数据标注的耗时与人力成本,提升模型开发效率,在样本数量较多的情况下,成效尤为突出。
4.海量训练数据自动生成
当训练数据不足时,合合信息文字识别训练平台可基于模板和语料知识库,自动生成海量虚拟训练数据。虚拟训练数据自动替换了样本内容但保留了图像版式,可快速扩充训练集,提升模型训练效果。
5.零门槛,无需算法基础
全可视化开发,无需算法基础,零门槛操作。集模型创建、数据标注、模型训练、模型测试、模型部署于一体,任务集中管理,操作简单,零基础OCR开发者也可完成模型开发。
6.算法模型丰富,识别精度高
系统内置五大预训练算法模型,用户可灵活根据文档版式特征选择模型。基于合合信息深耕十余年的智能文字识别技术与商用模型实训经验,预训练模型训练基础扎实,识别准确性高、识别速度快、鲁棒性高。
7.开发周期短
自动标注数据、自动训练与测试模型,大幅度压缩模型开发时间,相比传统定制模型周期显著缩短。

场景一:金融机构集中运营
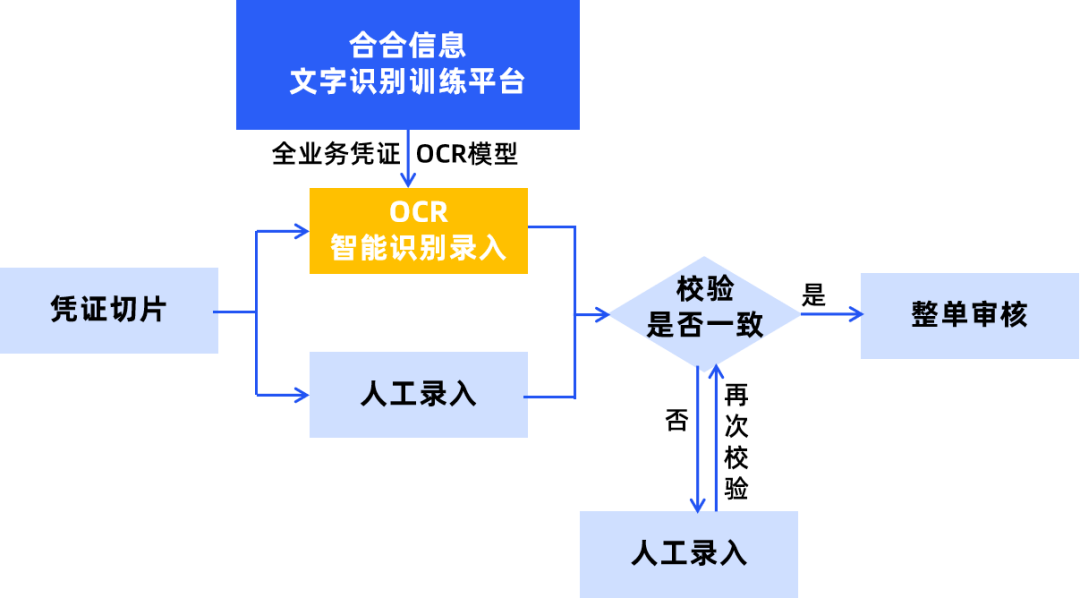
当前,头部银行与券商纷纷推进集中运营建设,形成分支机构前台受理、专门机构后台集中处理的业务运作模式。在集中运营中,长流程的业务被切分成“前台受理-录入-审核-授权”几段清晰分离、相对短的流程。录入环节通常为“两录一校”,两位录入员分别录入凭证切片上的信息,校验员判断两录结果是否一致。
基于合合信息文字识别训练平台可生产针对多类型凭证的信息抽取模型,将其中一录由人工录入转变为智能文字识别录入,系统自动识别提取切片信息,另一录依然为人工录入,将智能文字识别结果与人工录入结果进行一致性校验,在保证录入流程严格准确的基础上,大幅度提升了业务效率,降低人力成本。
场景二:银行后督
银行需要根据会计规范与银行相关法规,对行内各网点的业务交易进行事后监督,通过对业务凭证、营业日报表等进行复审、核对、检验,实现重点监督、差错处理与综合对账。传统事后监督流程中,由于人工审核的人力与效率的局限性,无法对全业务进行审查,只能手工抽查部分大额交易凭证,后督业务覆盖不全面。
合合信息文字识别训练平台可输出覆盖全类型凭证的智能文字识别能力,如:转账支票、现金支票、进账单、收款凭证、电子转账凭证、信汇凭证、托收凭证、收费凭证、现金交款单、银行承兑汇票、商业承兑汇票及各类申请书、缴款书、通知书等,赋能银行后督系统对全业务凭证需审核字段进行自动识别提取,后督员依照审核要求,对字段相互间信息、字段与身份证件信息、联网信息等进行核对校验,建立全业务后督体系,充分发挥后督防弊纠错、规范行为、保证资金安全的作用。
场景三:跨境贸易反洗钱审查
应国内与国际监管要求,外资银行需要对从事跨境贸易的企业客户在行内的每笔资金交易往来进行排查,确保交易有实际匹配的跨境贸易活动,严格识别与筛查洗钱风险。由于跨境贸易的凭证种类多样,且有大量的不固定版式凭证,如:海外invoice、订单合同、运输单,人工审核方式需要耗费大量人力,传统OCR模型对不固定版式的识别精度较低,需要高度定制。
基于合合信息文字识别训练平台,银行可自主对固定、半固定、不固定版式凭证进行识别模型创建和迭代训练,持续提升识别准确率,实现AI全生命流程管理,通过对报关单、核注清单、进账单、信用证开立申请书、海外invoice、订单合同等贸易凭证的智能识别、匹配、审核,构建智能化的跨境贸易反洗钱审查体系。
场景四:供应链与物流管理
企业供应链与物流管理中,涉及到发票、合同、运输单、货物清单、出/入库单等,跨境贸易更涉及到托书、提单、箱单、海外发票、签收单、原产地证书等多类型单证,供应链单证种类繁多且数量巨大,单证录入、审核、电子化归档需要花费大量人力与时间。
企业可通过合合信息文字识别训练平台实现模型创建、数据标注、模型训练、模型测试、模型部署的一站式OCR开发,实现对多类型、多版式供应链票据的智能分类与信息抽取,按照业务需求智能提取单证中的所有字段信息如:单号、商品名、金额、日期等,实现单证信息采集、审核、确认自动化,并支持对接ERP系统,赋能供应链管理智能化升级。

▶ 某上市城商行
某上市城商行多部门有大量的标准证照、固定或不固定版式凭证、银行交易流水、财报等识别需求,文档包含印刷体与手写体,中、英等多种语言。行内还需要根据业务拓展需求与监管要求,快速响应,新增更多类型的证照识别能力,自主建模识别新类型的票据、报表等。
该城商行与合合信息合作,私有化部署了合合信息文字识别训练平台,通过自主模型创建、训练、部署上线与持续迭代,满足了身份证、银行卡、驾驶证、行驶证、结婚证、户口本、房产证等证件识别,现金支票、转账支票、进账单、存单、结算业务申请书、代发工资流水等业务凭证识别,增值税专用发票、增值税普通发票、火车票、出租车票、定额发票、机动车销售统一发票等票据识别,以及财报识别分析、证照风险检测等多业务场景需求,赋能集中作业中心、运营管理部、风险管理部、小企业信贷中心、财务企划部等行内部门。并且,仅需要一位运维人员,即可实现对行业OCR服务的统一管理。
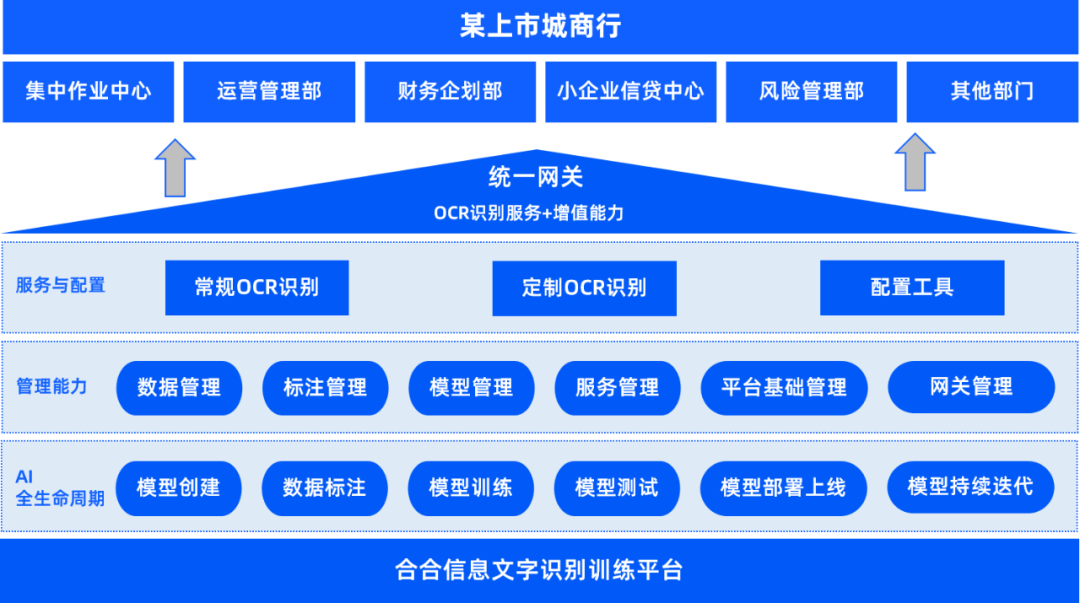
同时,合合信息助力该城商行搭建数据回流交换平台连接集中作业平台与文字识别训练平台,将实际业务中产生的标注数据回流至文字识别训练平台,不断迭代优化模型,提升模型抽取精度,赋能全业务条线高效智能审核。
▶某全国性股份制银行
某全国性股份制银行希望搭建行内通用的OCR识别服务平台,更加高效智慧地满足各业务条线需求。该行与合合信息合作,私有化部署了合合信息文字识别训练平台,输出了身份证、银行卡、营业执照、增值税发票、全文识别、表格识别等常规OCR模型,支付凭证、进账单、支票、税收缴款书等定制化、个性化OCR模型,以及60+(数量持续增加)类型凭证的自动分类模型。

该行运营管理部的集中运营业务中需要“两录一校”,数据录入团队超过100人,基于合合信息文字识别训练平台输出的智能分类与智能文字识别能力,大幅度降低了人工录入工作量,节约业务时间,实现降本增效。
此前,该行通过第三方厂商驻场定制非标凭证的OCR模型,不仅定制成本高、周期长,每当凭证有版本变化,之前定制的模型就不再适配,需要二次优化训练。部署合合信息文字识别训练平台后,在自主创建适配当前凭证类型的OCR模型,并一键训练与测试,样本量不足时还可自动生成海量标注好的训练数据用于模型训练,提高各类凭证批量定制化识别的精准度,快速高效地响应业务需求。当凭证版式发生变化时,行内可自主迭代模型,操作简单,开发周期短,工作效率高。
▶某外资银行
外资银行需要对办理跨境结算的企业客户进行反洗钱审核,确保交易有实际匹配的跨境贸易活动。某外资行基于合合信息文字识别训练平台,实现了对报关单、进账单、海外发票、订单合同、运输单等固定与不固定版式的贸易凭证的智能分类、信息抽取、审核。
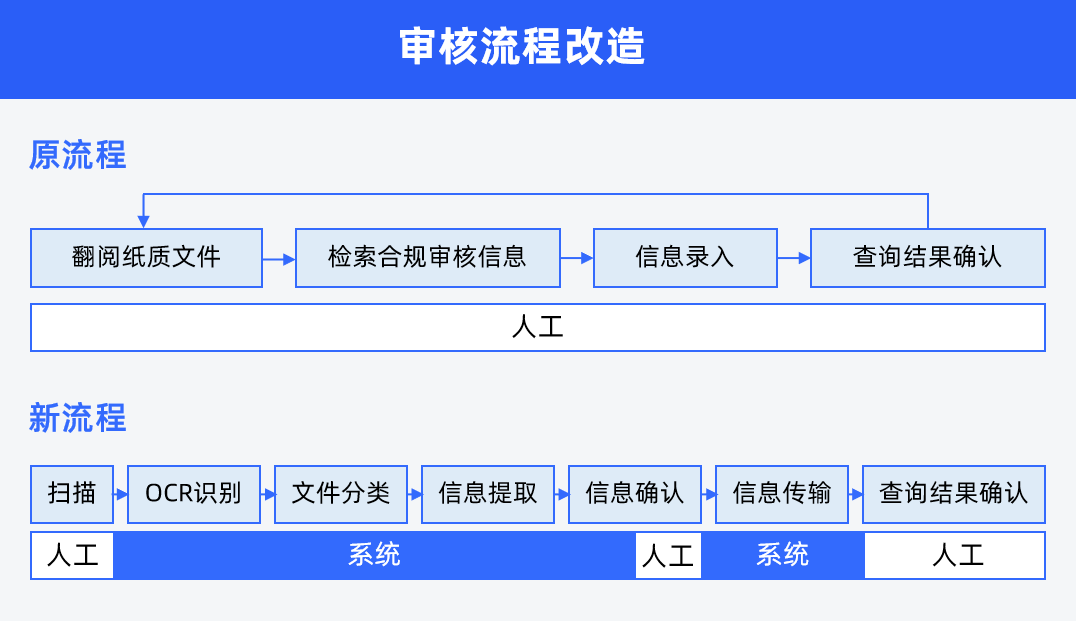
基于AI技术改造审核流程,该行实现了跨境业务的合规审核自动化,业务处理时间较原来缩减了90%,在大批量处理时效果尤为明显,录入错误也明显减少,整体业务处理效率得到极大提升。
合合信息文字识别训练平台SaaS版
合合信息文字识别训练平台除了上述的私有化版本之外,近期,重磅推出了SaaS版。点击图片即可了解详情。
























