长文本NLP信息抽取:一站式自主训练开发模型,合同/报告/保单全类型长文本通用!
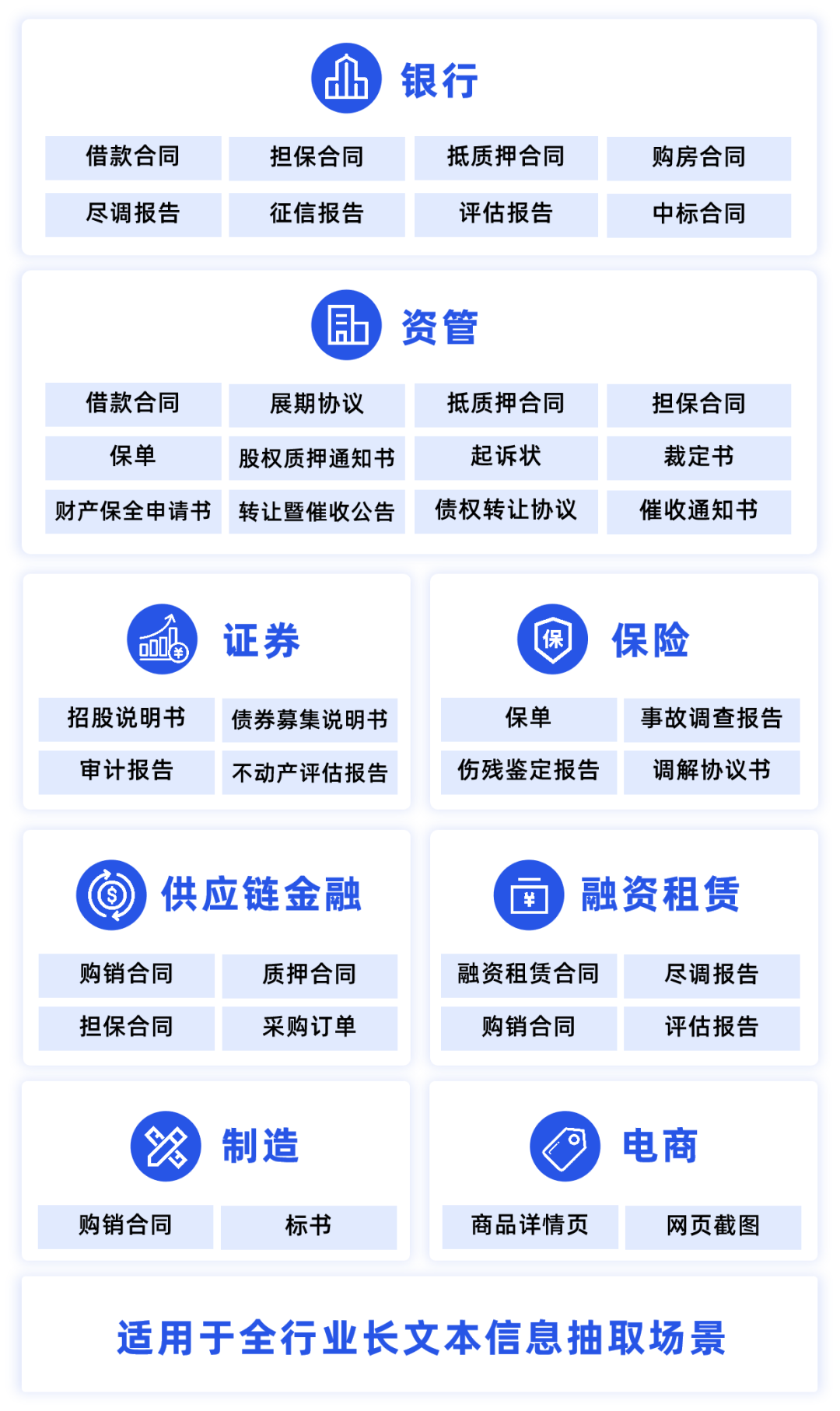
在银行、证券、资管、保险、供应链金融、制造、电商平台等各行业的审核业务中,有大量合同、报告、标书、保单等长文本的特定信息抽取需求。比如证券业务中,需要处理多达数百页的招股说明书、债券募集说明书、审计报告、不动产评估报告等文档;资管业务中,需要处理大量的借款合同、担保合同、抵质押合同、转让协议、裁定书、判决书、公告等非固定版式的债权相关文件,需要耗费审核人员大量时间翻阅、检索、定位信息,从庞杂的长文本信息中提取出关键信息。
由于这些长文本文档的版式不固定、类型多样、页数较多,且内部常常含有表格、印章等复杂要素,传统OCR技术往往较难实现高可用性的信息抽取效果。
合合信息基于先进的自然语言处理(NLP)技术,有效解决了各类型不固定版式长文本的关键信息智能抽取难题,推出了合同机器人等垂直场景产品,并通过研发文字识别训练平台,内置成熟的NLP与深度学习算法,助力企业自主开发针对自身业务场景的定制化长文本信息抽取模型。


合合信息文字识别训练平台,目前已内置信息抽取(锚点)、信息抽取(K-V)、信息抽取(NLP)、信息抽取(长文本)、分类识别五大算法模型,提供了集模型创建、数据标注、模型训练、模型测试、模型部署于一体的机器学习服务。
企业可通过合合信息文字识别训练平台的“信息抽取(长文本)模型”,自主开发针对合同、报告、法律文书等不同类型长文本的NLP信息抽取模型,零AI算法基础开发者也可轻松操作,有效解决了定制开发周期长、成本大、基于数据保密性要求无法对外部厂商提供训练样本的痛点,实现自主可控的AI开发与迭代。
- 操作流程
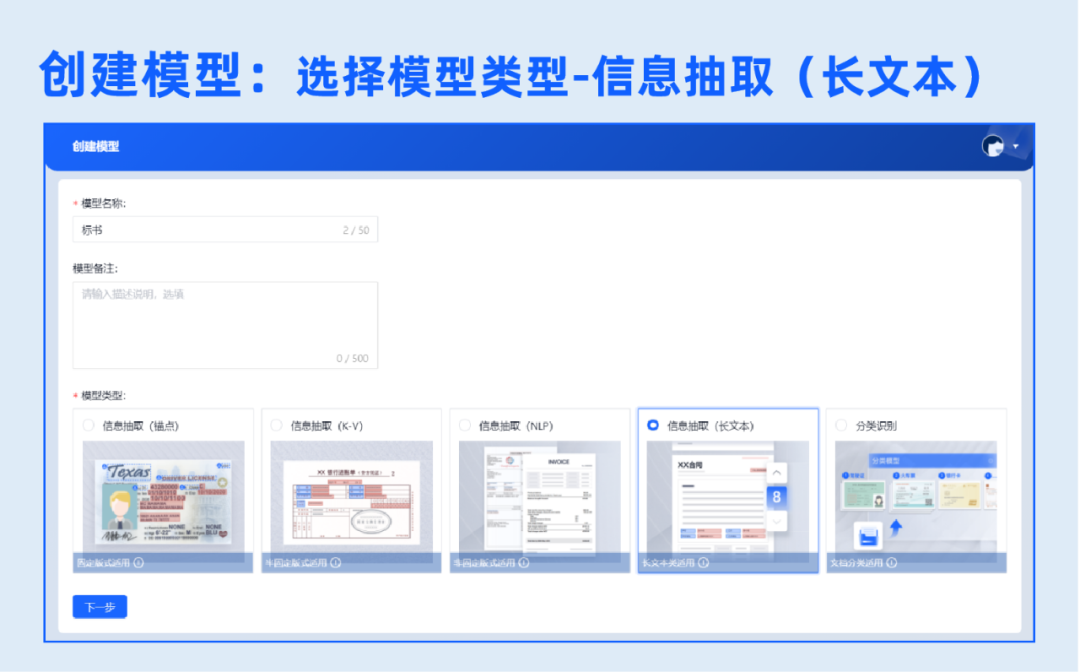
1.创建模型
设置模型名称,选择模型类型:信息抽取(长文本)。
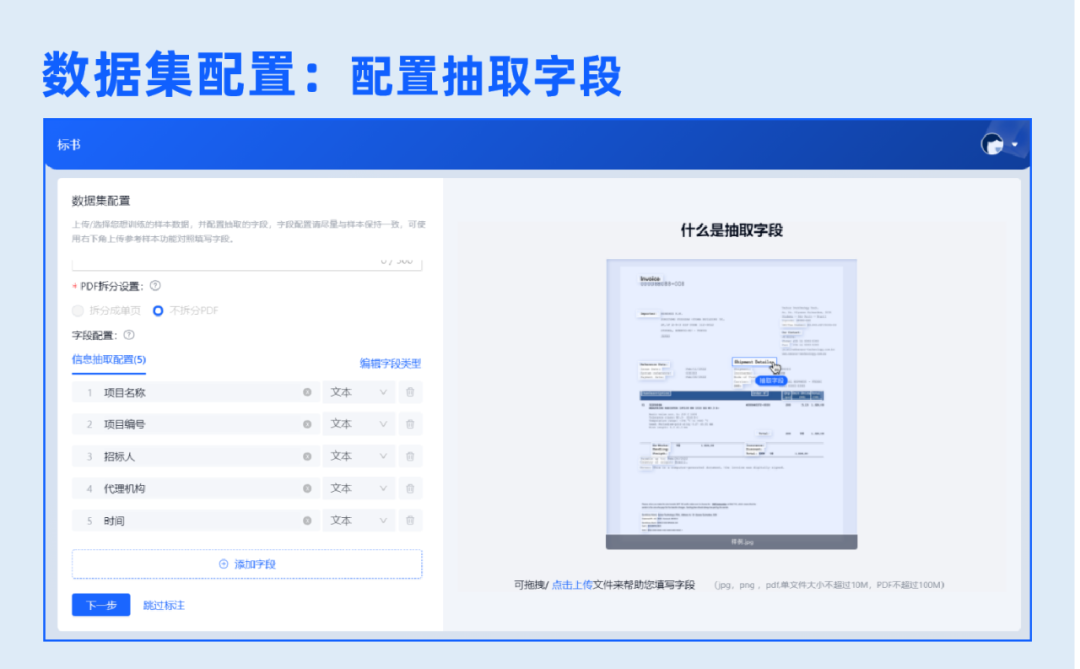
2.数据集配置
设置抽取字段,可配置文本字段类型与印章、表格、手写、一维码、二维码等非文本字段类型。
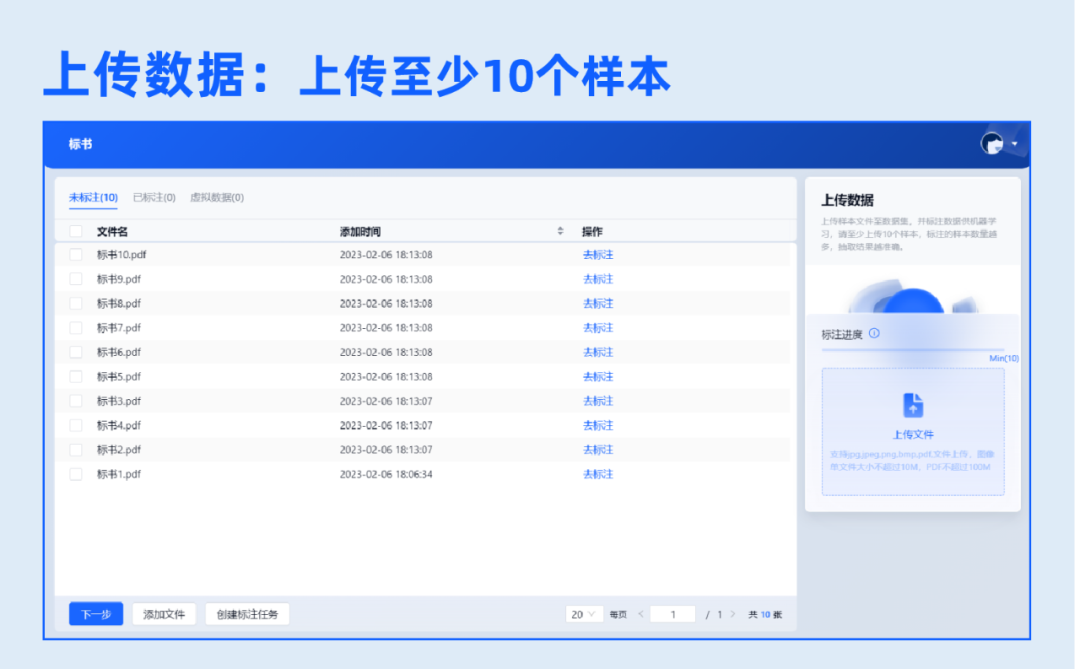
3.上传数据
上传至少10个样本数据,支持生成虚拟数据,标注的样本数量越多,抽取的效果越准确。
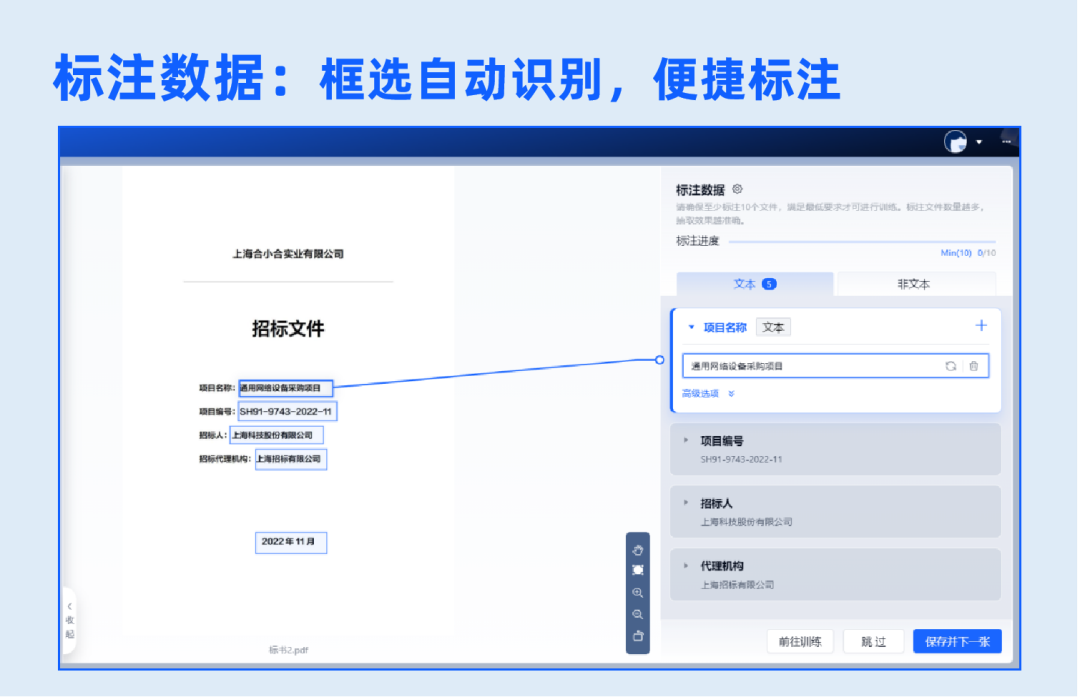
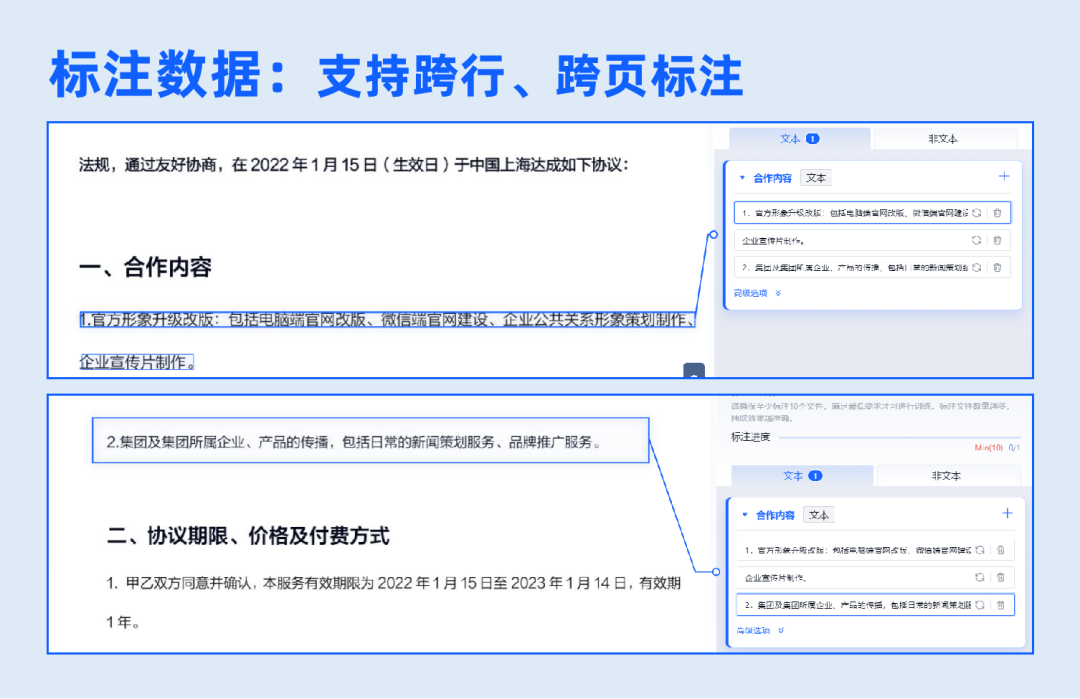
4.标注数据
在图像上框选对应字段,自动识别,支持跨行、跨页标注,便捷完成数据标注。
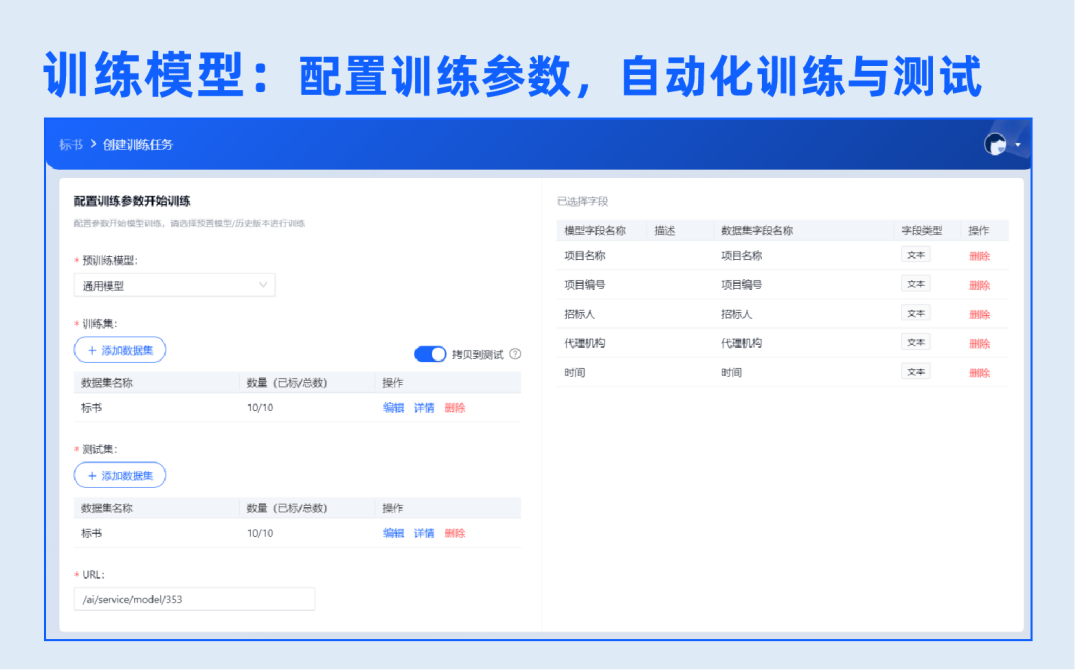
5.训练模型
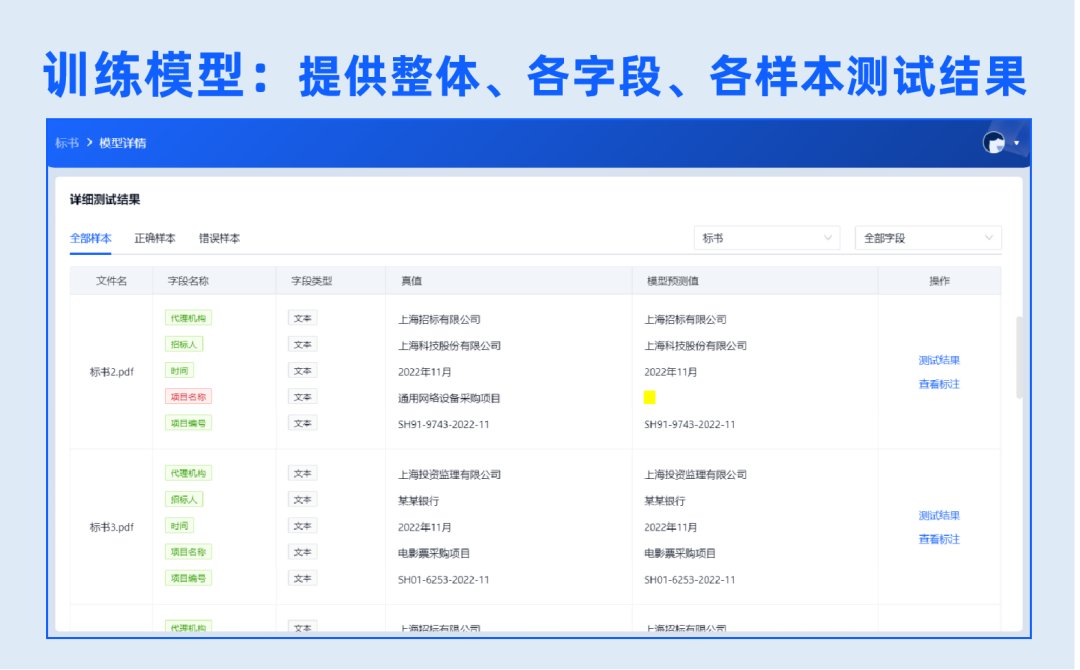
选择预训练模型、迭代轮数,一键即可自动化完成模型训练、构建、测试全流程,并提供整体、各字段、各样本测试结果。可在原模型版本基础上,持续迭代新版本。
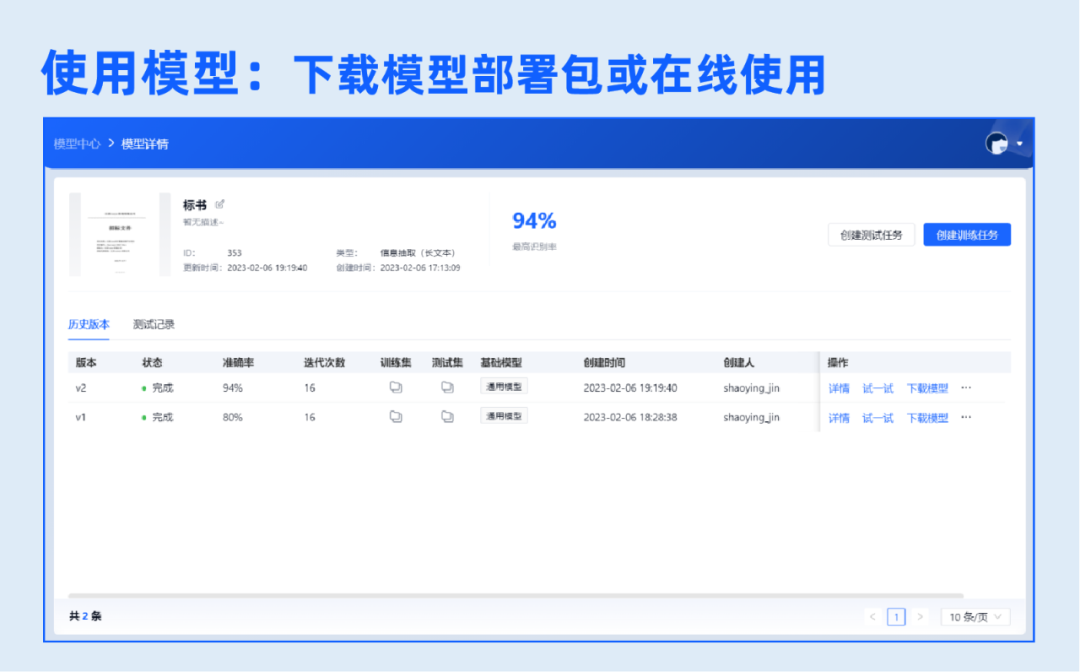
6.使用模型
下载模型部署包,一键部署服务器,同时支持在线使用、API调用。在私有化部署场景中,通过服务资源调度,只需要少量显存即可实现在线“试一试”。

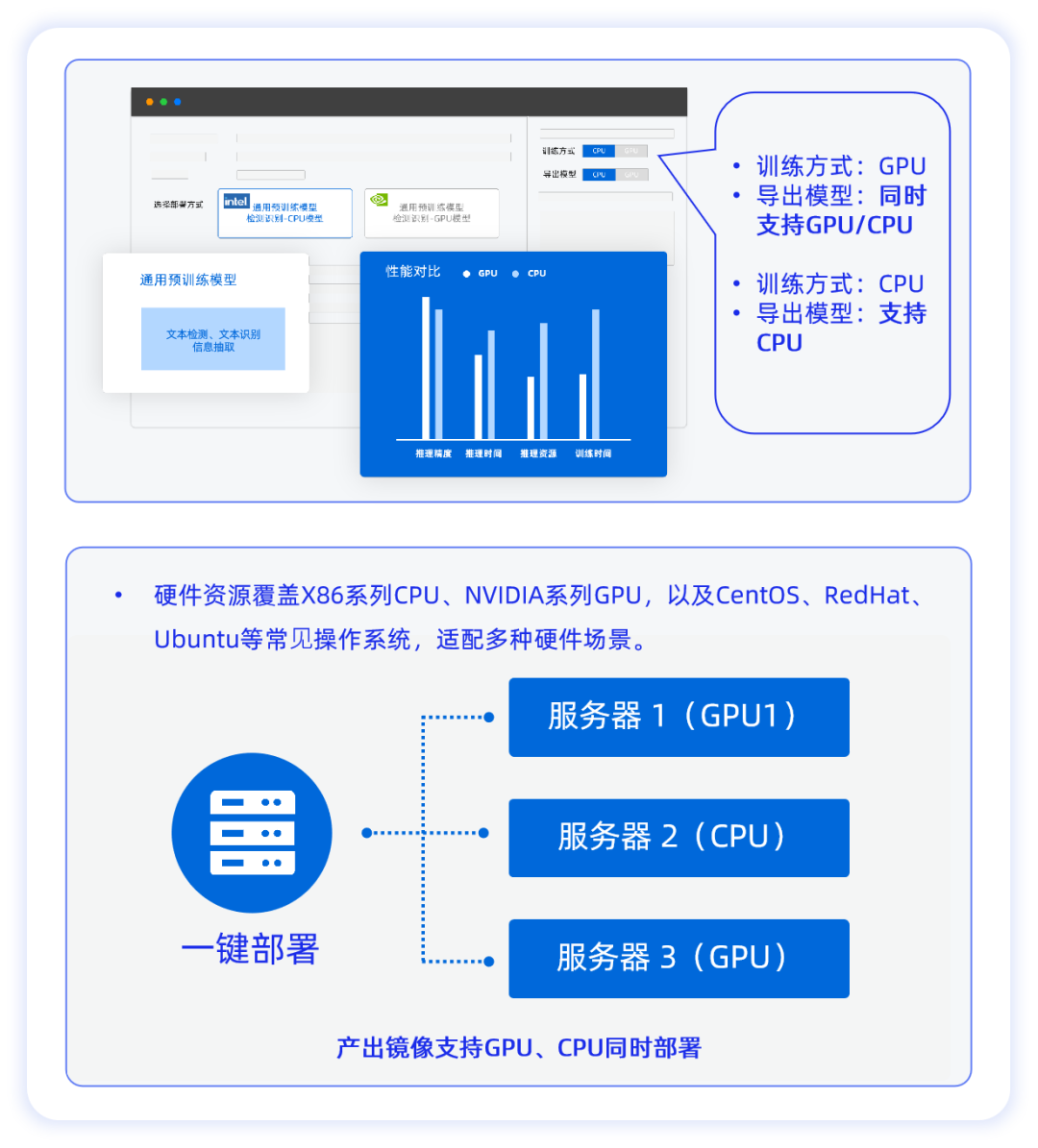
1.GPU/CPU训练与部署
合合信息文字识别训练平台支持GPU/CPU混合训练、混合推理部署、多模块合并,支持单GPU训练和纯CPU训练推理。企业可以在现有的硬件基础上直接部署文字识别训练平台,不需要额外的硬件投入,可降低企业硬件改造成本,灵活性高,鲁棒性强。
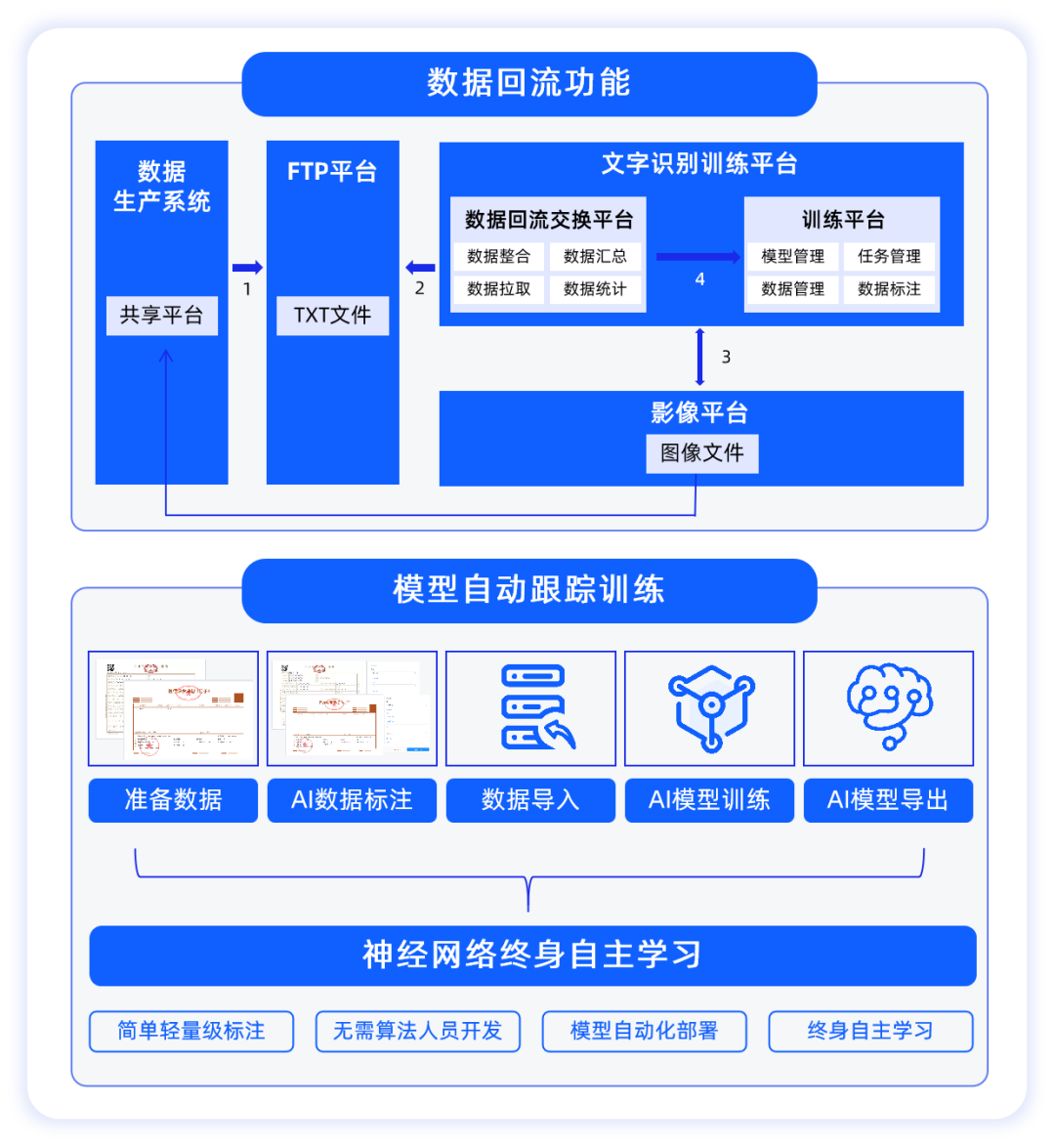
2.数据回流,终身自主学习
合合信息文字识别训练平台具备数据回流功能,通过搭建数据回流交换平台连接业务平台(数据生产系统)与文字识别训练平台,将实际业务中产生的标注信息数据进行拉取、整合、统计后回流至文字识别训练平台,并用于对应模型的训练,提升模型的识别准确率,实现“在业务场景中越用越好用”的持续迭代效果,真正做到了智能化和终身自主学习。

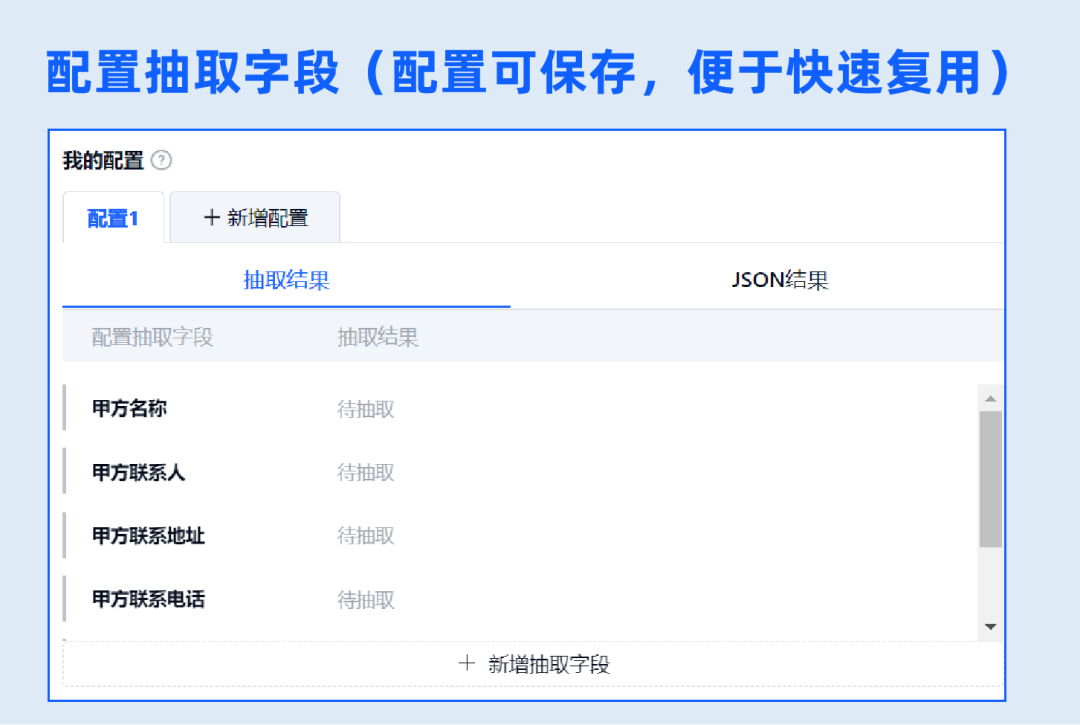
除了可自主训练开发NLP信息抽取模型的文字识别训练平台,合合信息还推出了通用长文本NLP信息抽取产品,开通即用,无需训练。一个模型即可满足各类文档的信息抽取需求,不限文档类型与版式,泛化能力强。
企业只需上传文档,配置需要抽取的字段,比如合同抽取配置:甲方名称、乙方名称、签约时间、付款方式等,即可实时抽取出配置的字段结果。

该产品无需定制开发,技术成熟可用性高,支持API、私有化部署、端侧SDK、AIoT等多种部署方式,已落地于多家大型集团业务流程,只需要少量人工辅助复核,即可以较低的综合成本实现长文本审核效率的大幅度提升。