TextIn xParse + 大模型
立即咨询
免费试用
如果使用TextIn xParse 智能文档解析,这些困境可以迎刃而解


非结构化信息难利用
企业大模型知识库建设面临多源、多格式、多模态的文档(如PDF/扫描件等),包含海量非结构化信息(如图片/表格/公式/手写内容等)难以有效解析、识别和提取,造成企业内部大量信息无法被有效利用

大模型幻觉难解决
大模型幻觉普遍存在,普通用户也难以识别那些“看似正确,实则错误”的信息。大模型生成的错误回答,不仅会影响企业高效运作,更会导致企业错误决策,造成损失

安全性能难兼顾
企业想使用性能更强劲的大模型,但又担心企业隐私数据被泄露。如果自己训练垂类大模型或小模型,不仅费时费力,性能也难以和国内外主流大模型匹敌
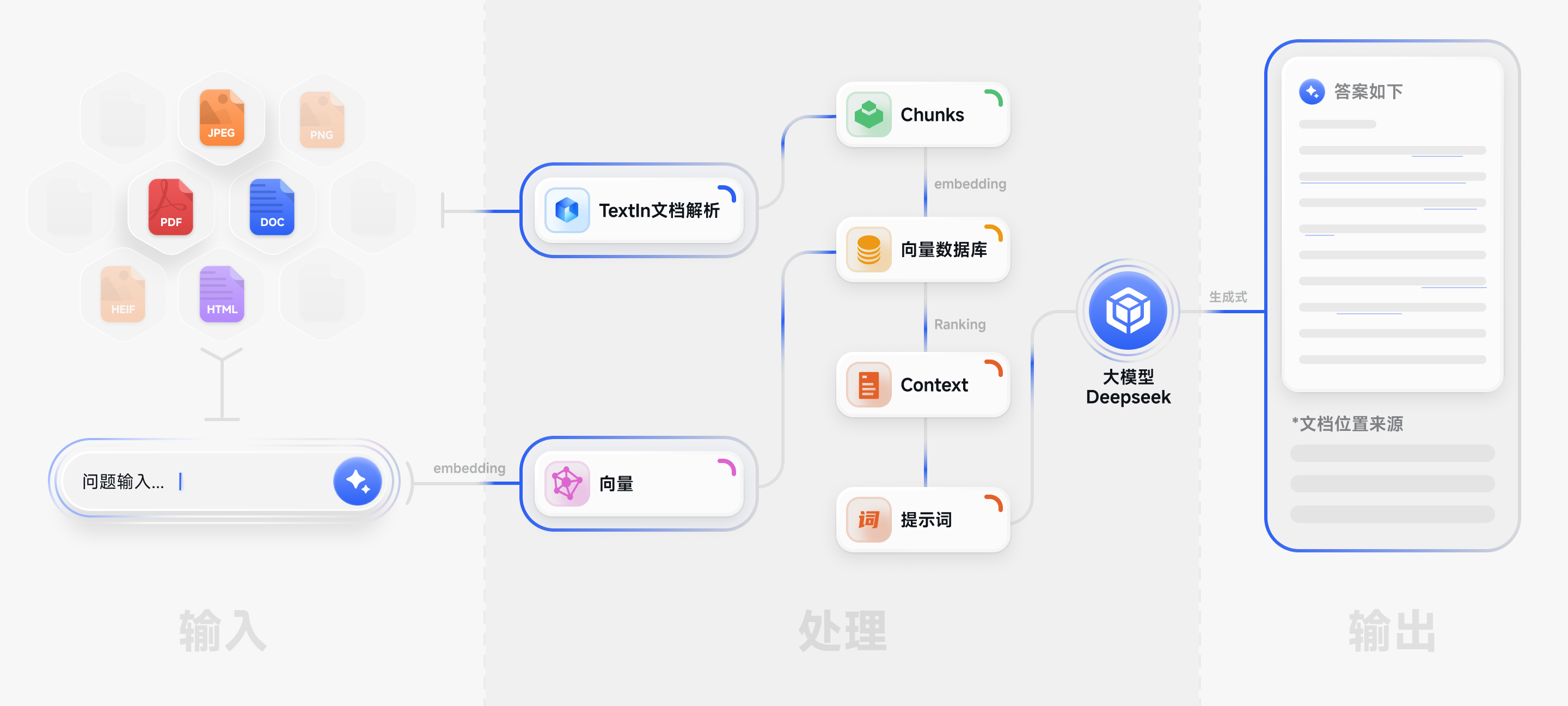
产品方案架构
立即咨询
免费试用
TextIn xParse 智能文档解析,帮助企业真正实现大模型知识库建设
多模态文档解析,表格识别更精准
兼容多种文件格式


一个接口,支持 PDF、Word(doc/docx)、常见图片(jpg/png/webp/tiff)、HTML 等10+种文件格式,实现多模态文档解析
支持复杂版面解析,提取多种信息要素
一次请求,即可获取文字、表格、标题层级、公式、手写字符、图片信息,并且支持按Markdown和Json格式输出给大模型
表格识别更精准
有线表、无线表、密集表,跨页表、单元格合并表都能精准识别
立即咨询
免费试用


解析速度极快,100页快至1.5秒
更快、更准
深度调优自研算法,不仅解析准,而且快,100页长文档PDF在线解析快至1.5秒。
支持大批量离线解析
支持离线自动批量解析处理,只需一次性上传大量文档,3天便可在后台高效精准解析500万页PDF。
立即咨询
免费试用
稳定性极高,成功率可达99.999%
高成功率
日均支撑数百万级调用量,成功率达99.999%
高稳定性
来自亿级用户体量APP的技术,稳定可靠
立即咨询
免费试用

更多产品和方案优势


接入方式灵活
支持实时API调用、异步离线调用、私有化部署 (可适配信创),全面满足各行业各类业务的场景诉求。支持对接V3和R1满血版及国内外主流大模型

数据安全,隐私无忧
不涉及与客户竞争业务,且拥有丰富的数据安全、灾备经验,历经科技行业头部公司、国有银行项目的验证

支持各类Agent
精准提取信息并提供标准输出,助力RPA自动化,增强自动化处理能力,较传统人工提升9倍效率,并且弥补Agent在非API系统交互的短板

支持结果溯源
支持对文档解析和问答结果的溯源,帮助用户快速、精准的确认信息来源,打破大模型回答来源“黑箱”,构建可信AI
多模态解析赋能多元业务场景
金融研报
招投标文件
教育应试
国家标准文件
医疗/科研文献
征信报告
企业知识库
文档翻译
为金融报告场景专项优化
表格更准,能力更全
·
适配年报中的各类有线/无线表
·
适配研报表格的复杂版式
·
表格支持解析为HTML语法
立即咨询
免费试用

TextIn xParse 智能文档解析,已在多个行业发挥价值
AI科技
教育科技
金融
生命医药
汽车制造
帮助某大模型公司突破文档解析瓶颈


大模型直接处理原生PDF、扫描件等非结构化文档时,常因元素遮盖、表格跨页、图文混排等复杂版面导致信息提取失败

合合信息通过智能文档解析技术,精准解析识别文字、图、表、公式等元素,并按Markdown和Json格式输出,从而解决大模型的阅读障碍。
答案准确率可提升约
90%+


响应速度缩短约
40%
立即咨询
免费试用
立即探索,解锁更多产品详情
申请试用























