合合信息文字识别训练平台SaaS版:多版式文档信息抽取,云端训练集成,零门槛操作
01
产品介绍
合合信息文字识别训练平台SaaS版是基于合合信息的深度算学习算法和能力,面向零基础的开发者或实际业务人员的文档信息智能抽取与训练云端工具,简单操作即可抽取标准和非标准模版文档的关键信息,支持文本与表格,识别率持续提升,最大限度地减少文档处理时间。

合合信息文字识别训练平台SaaS版可在云端进行数据标注、模型训练和集成等功能操作,帮助开发者或业务人员在极短时间内通过10张或10张以上的极少量样本数据实现从创建新的文档结构化任务、训练提升抽取效果,到实际测试和部署的全周期AI开发工作流,经实测,最短可在10分钟内完成抽取模型开发全流程。
02
操作流程
合合信息文字识别训练平台SaaS版进一步优化了页面交互与操作体验,通过进度条式的开发流程引导,直观展示操作步骤与进度,只需要简单三步即可生成特定文档场景的识别模型。

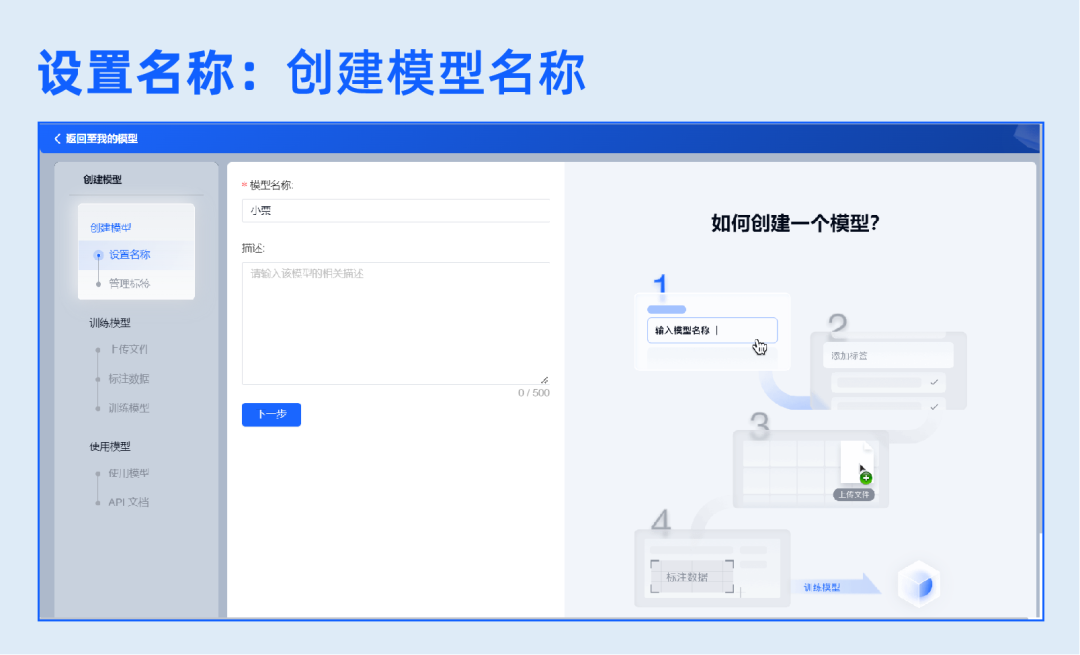
1.创建模型
自定义设置模型名称,自定义设置模型需要抽取的多个字段信息,可上传样本用于辅助抽取字段配置。
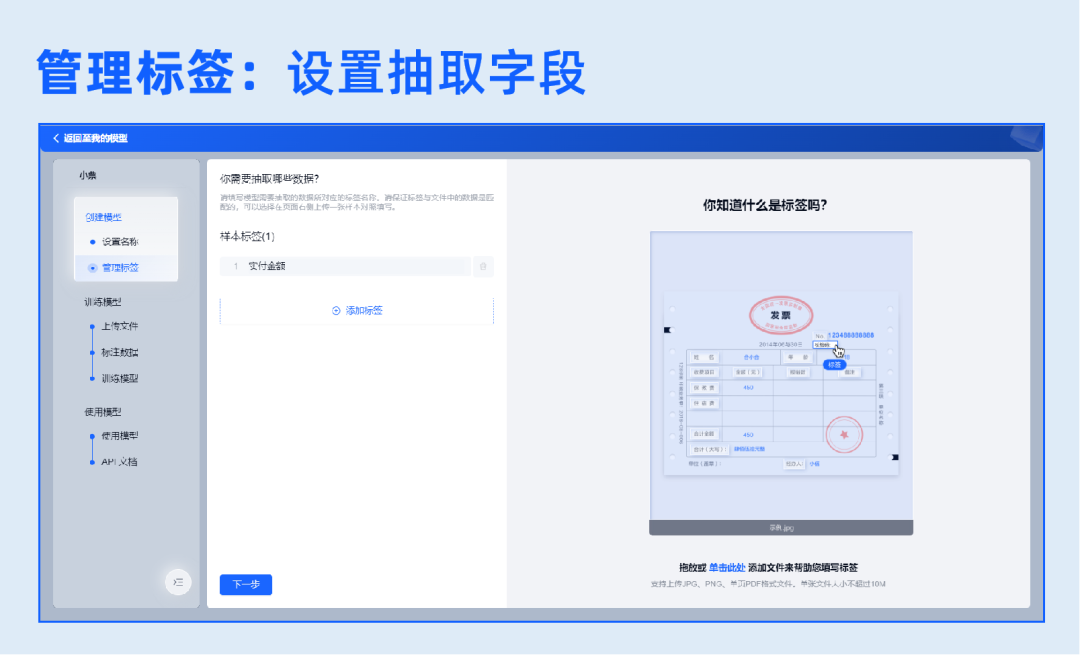
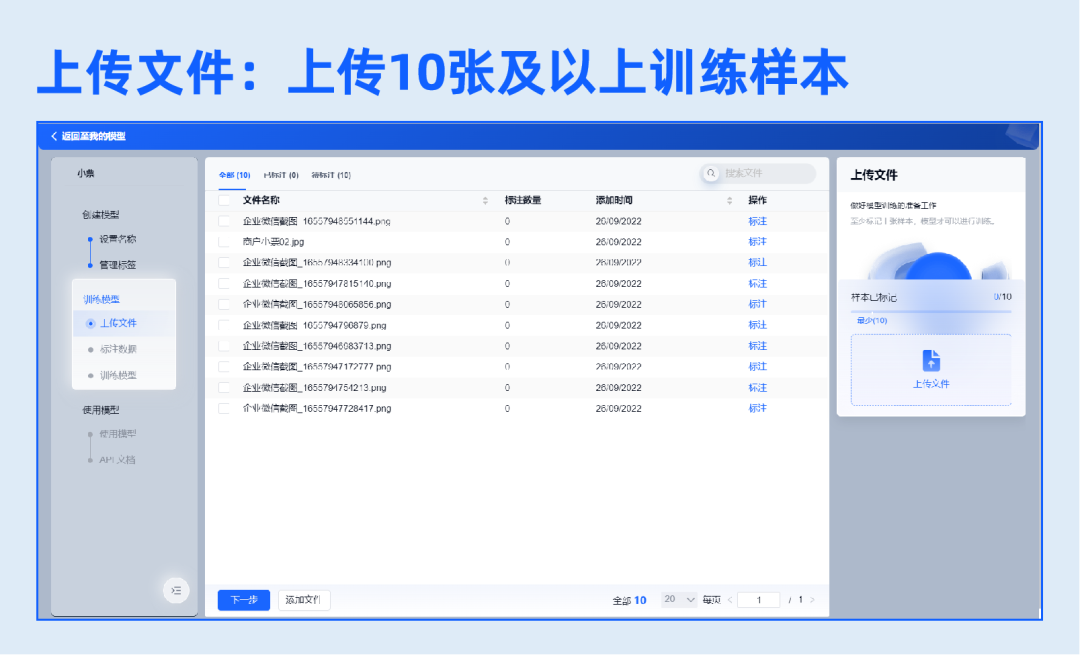
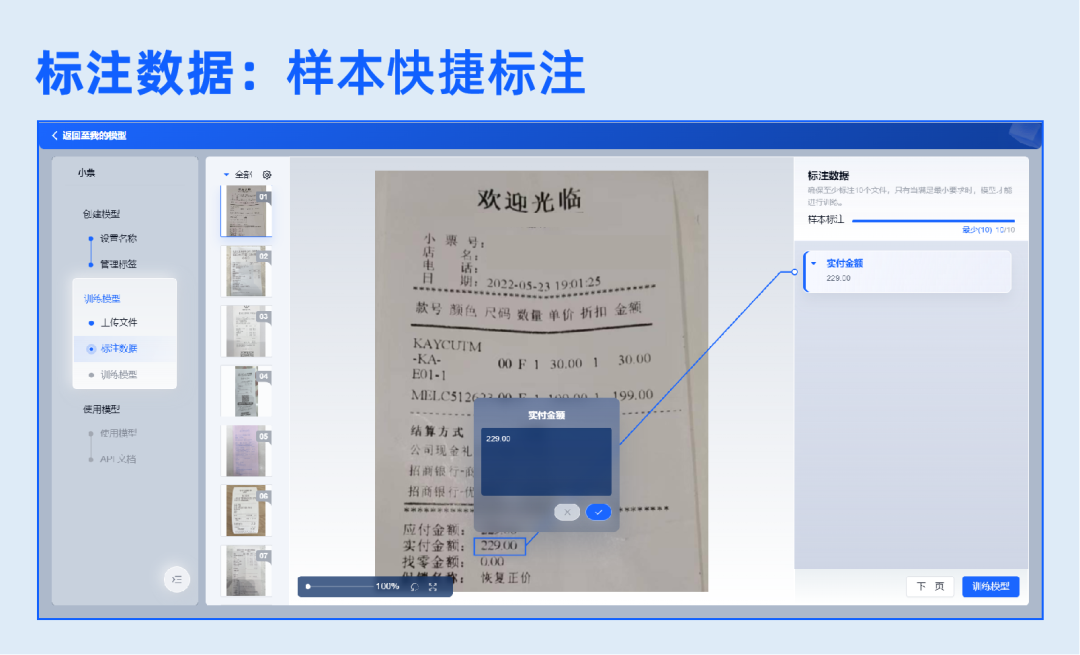
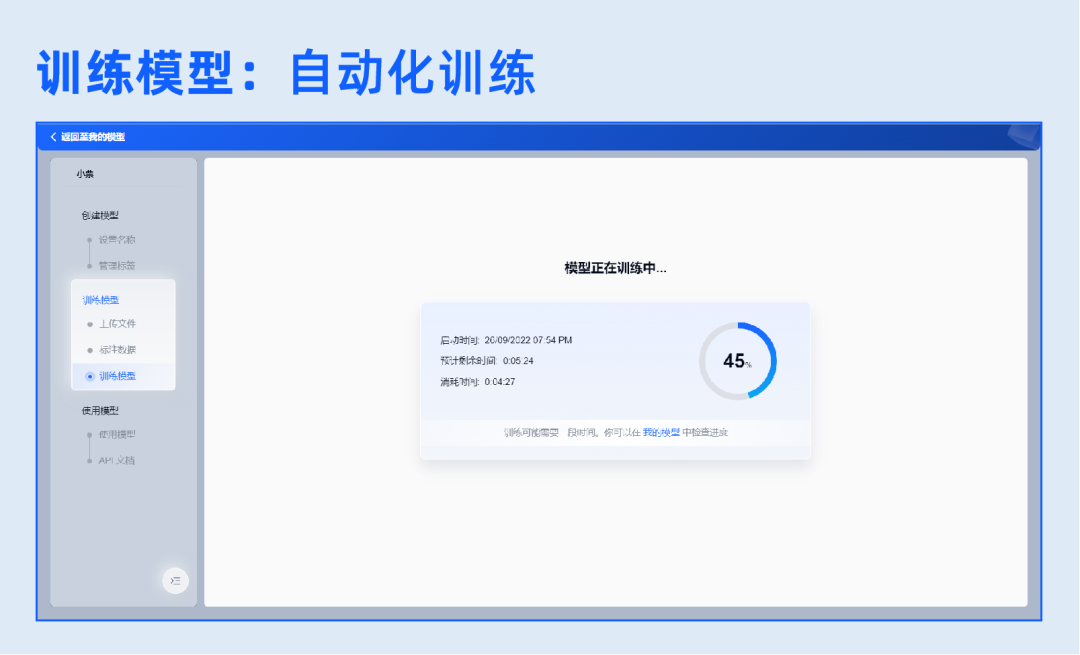
2.训练模型
一键上传样本数据,自动检验重复样本。根据设置的抽取字段自动标注数据,减少人工标注工作量。标注完成后即可发起训练任务,一键自动化训练,支持多维度展示训练进度,监控训练过程。
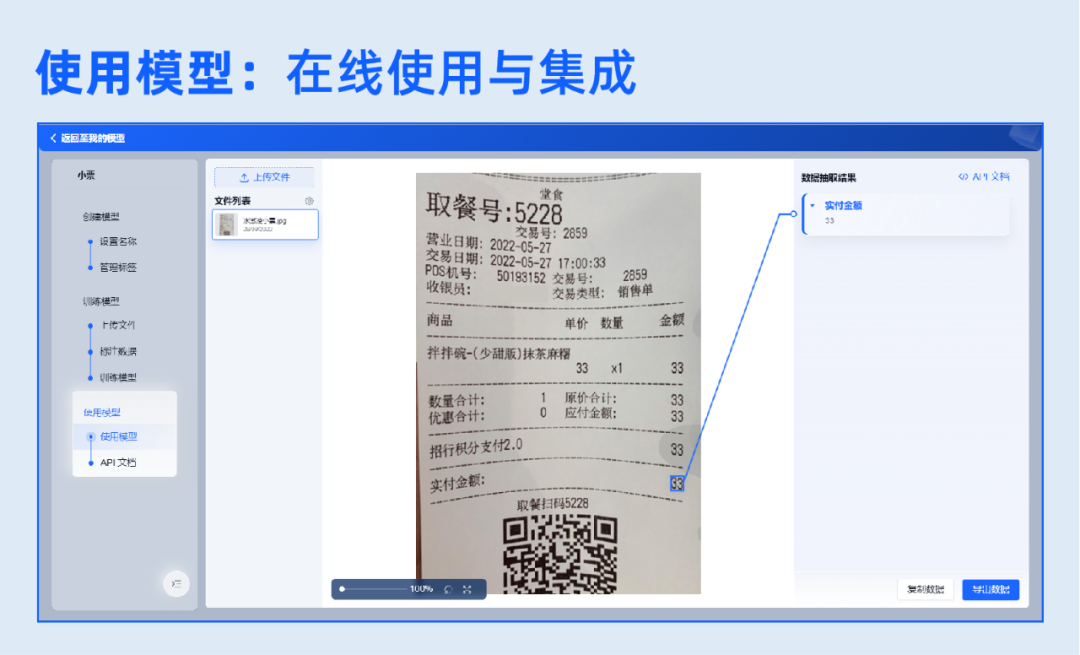
3.使用模型
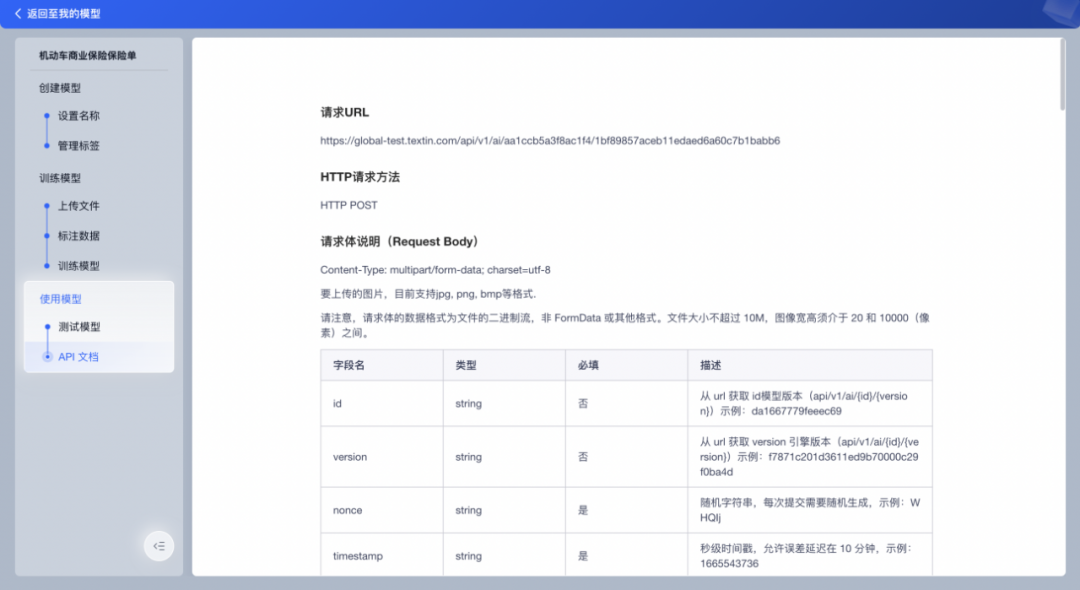
模型在线使用与API在线集成,支持批量上传图像,支持数据一键复制与导出。
03
产品更新
① 新增“表格信息抽取”,有线表与无线表通用
除了“文本”以外,“表格”是各类文档中的常见要素,尤其在供应链相关业务中,贸易单证往往都包含表格。但由于表格的多样性,根据有无框线可以分为有线表、少线表、无线表,且识别难度逐渐增加,在智能文字识别模型的训练开发中,表格信息抽取一直是个难点。
文字识别训练平台SaaS版新增“表格信息抽取”功能,支持有线表格与无线表格的信息抽取,覆盖文档类型从“文本”进一步扩展为“表格”与“文本+表格”,满足各类版式文档信息抽取需求。
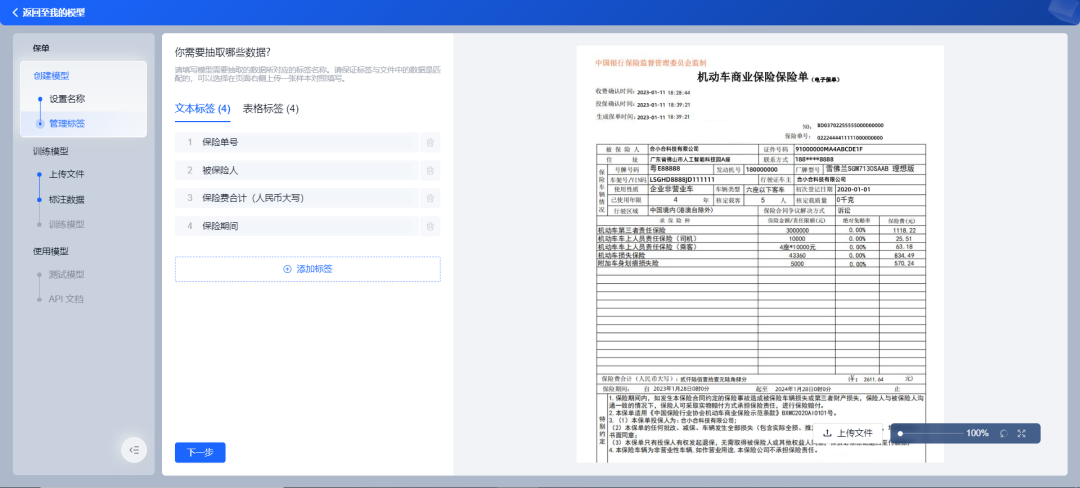
配置字段:
在“表格标签”中填写需要抽取的字段。
标注数据:
1.支持2种方式设置抽取的表格范围,支持表格线的增加、删除和移动。
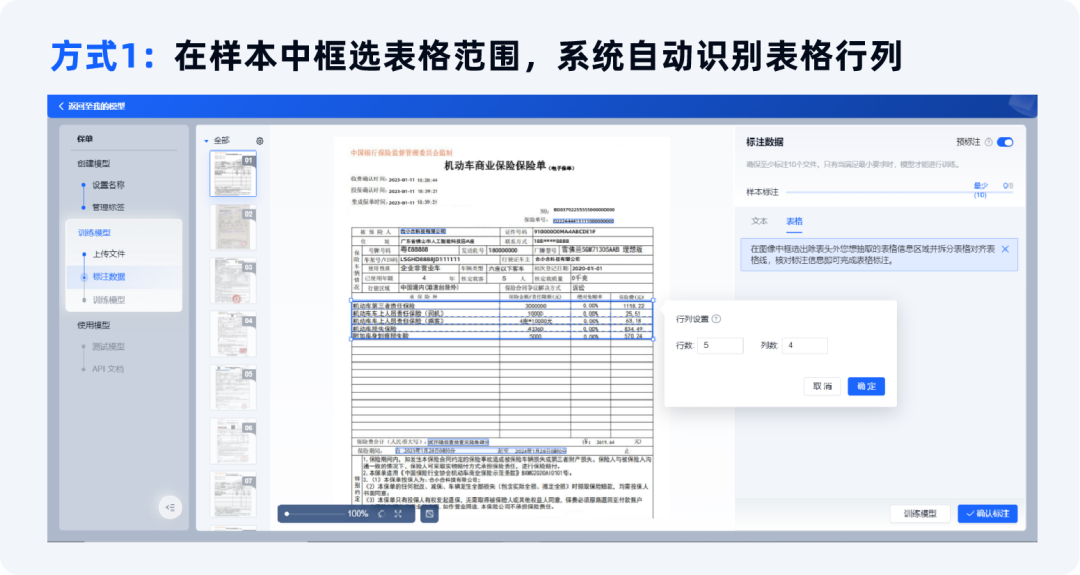
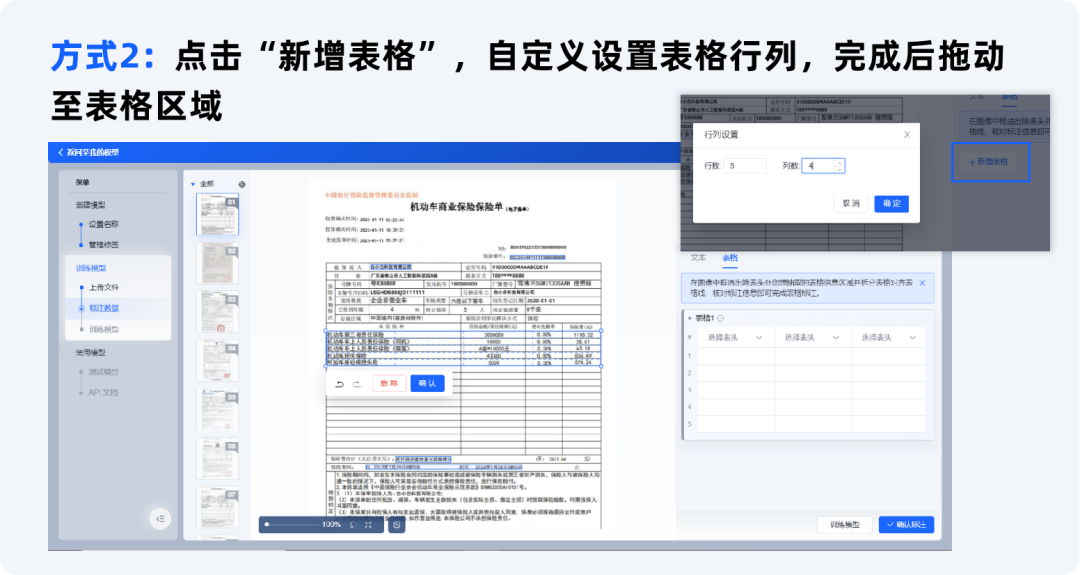
2.表格结构设置完成后,点击确定,进行信息抽取。
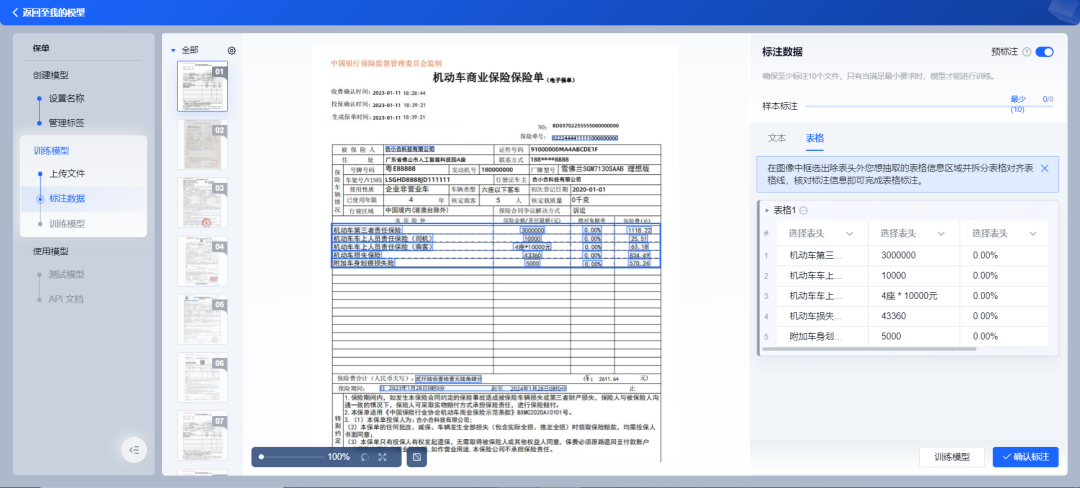
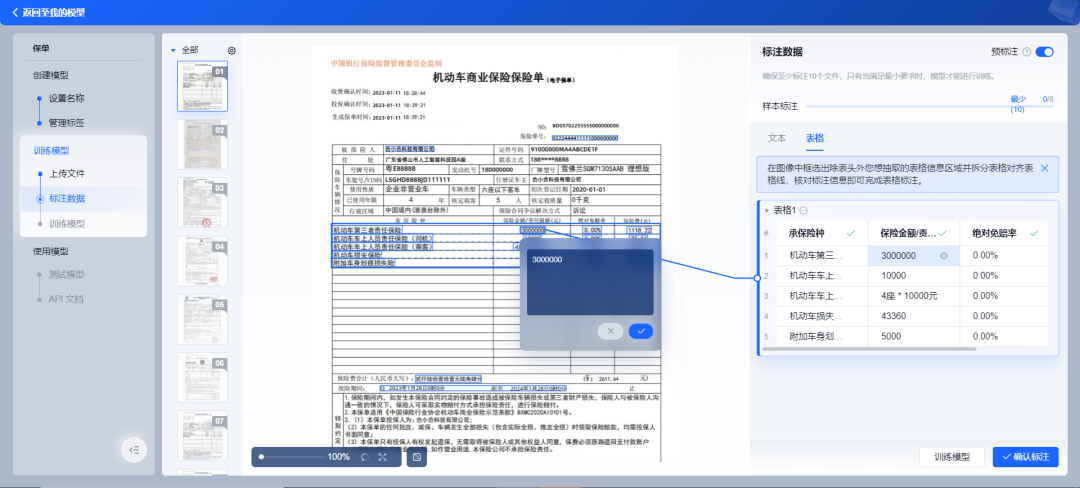
3.核查抽取内容,选择对应表头,可随时修改表结构,左右交互联动。
模型测试:
训练完成后进入模型测试,支持在当前页面中编辑表格内容和表结构,支持导出在线测试的抽取数据。
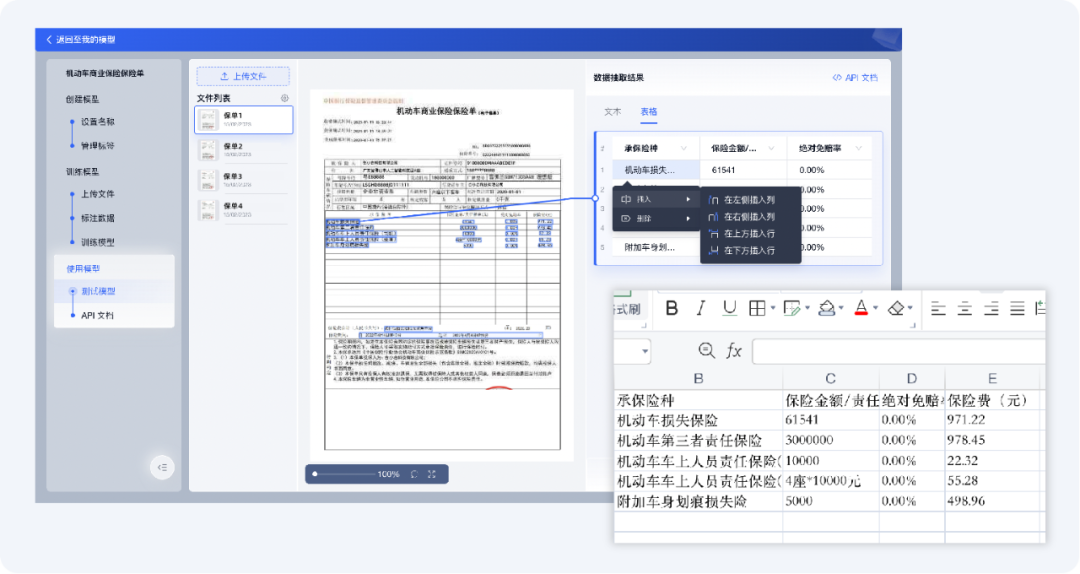
API集成:
提供该模型API文档供用户进行云端集成。同时,支持云端训练+私有化部署方案。
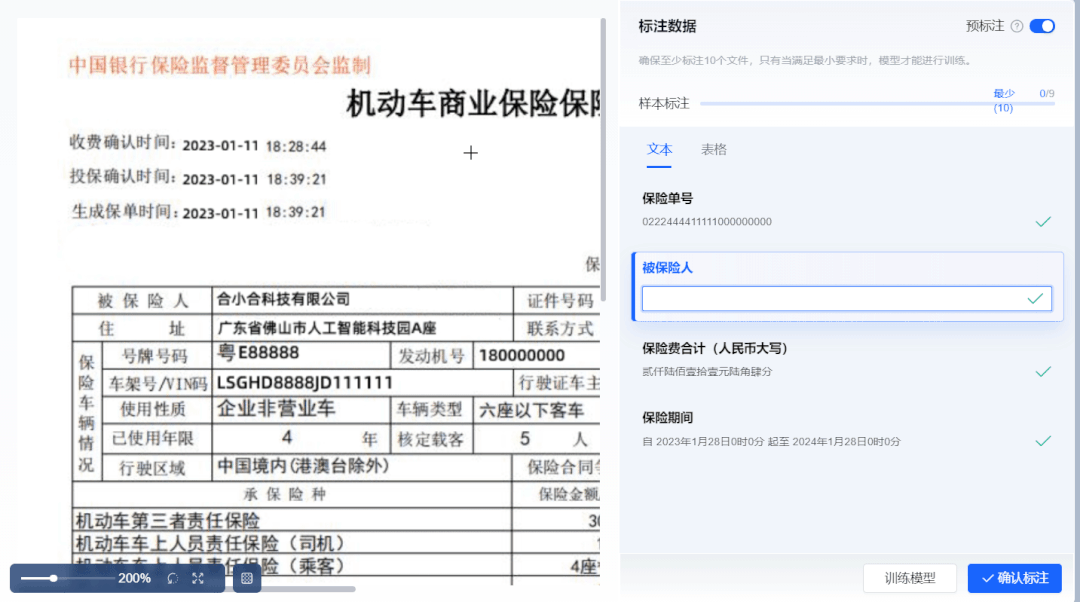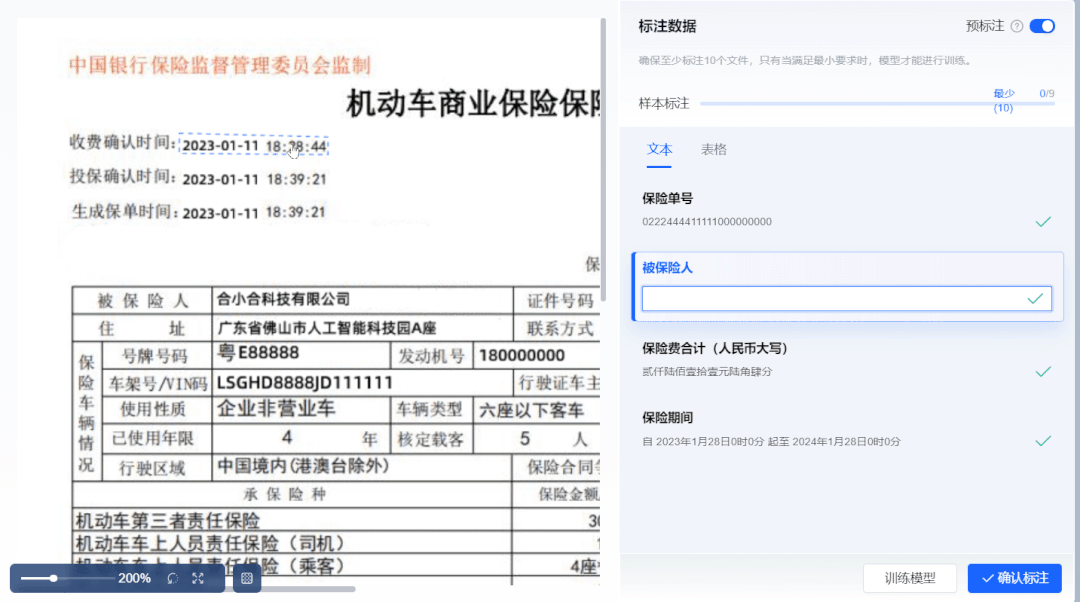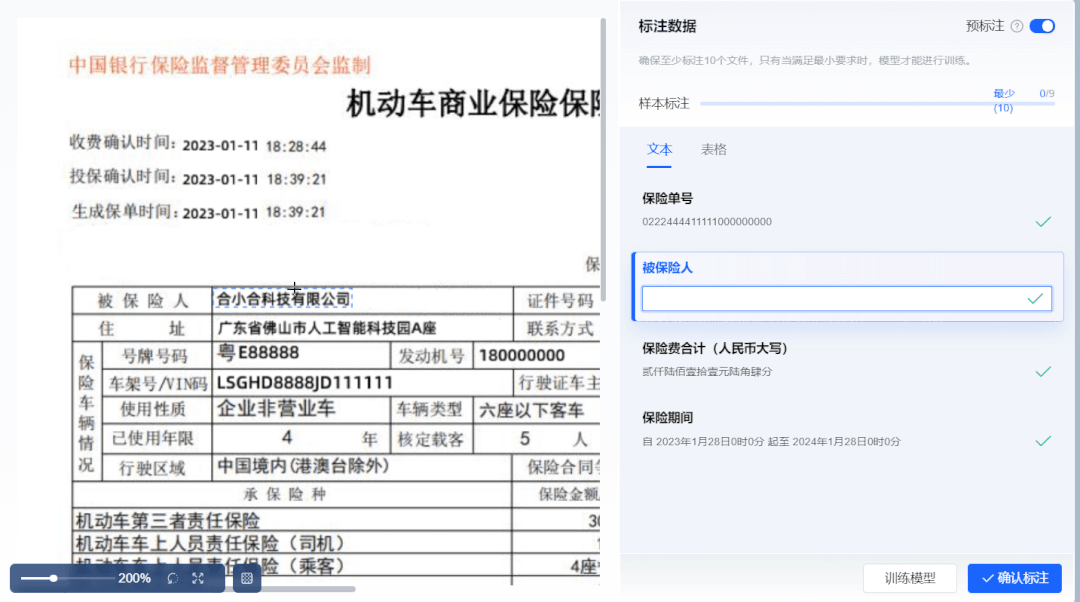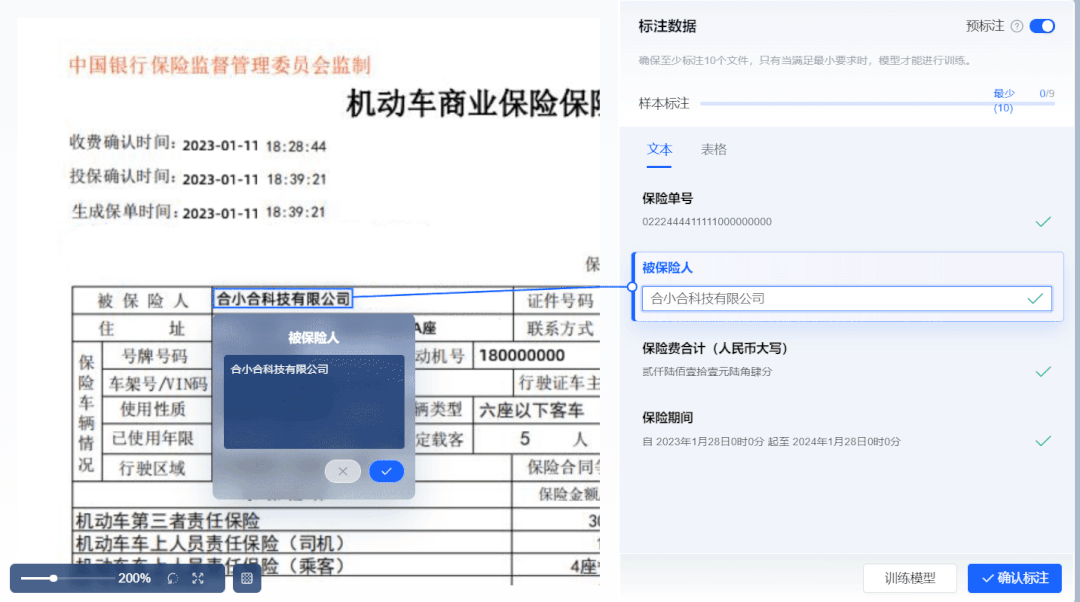
② 新增“智能机器标注”,系统自动标注数据
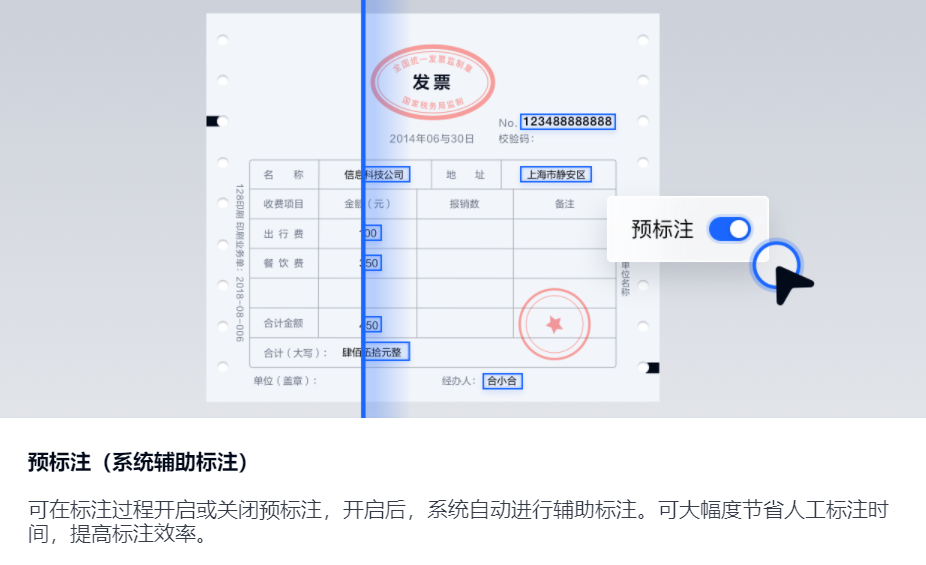
样本数据标注作为深度学习模型训练中最耗时的一项流程,需要投入大量人力。合合信息基于零样本学习算法,打造了智能机器标注能力。开启“预标注”模式后,系统自动根据用户设置的标签信息进行信息抽取,大幅度提升标注效率。
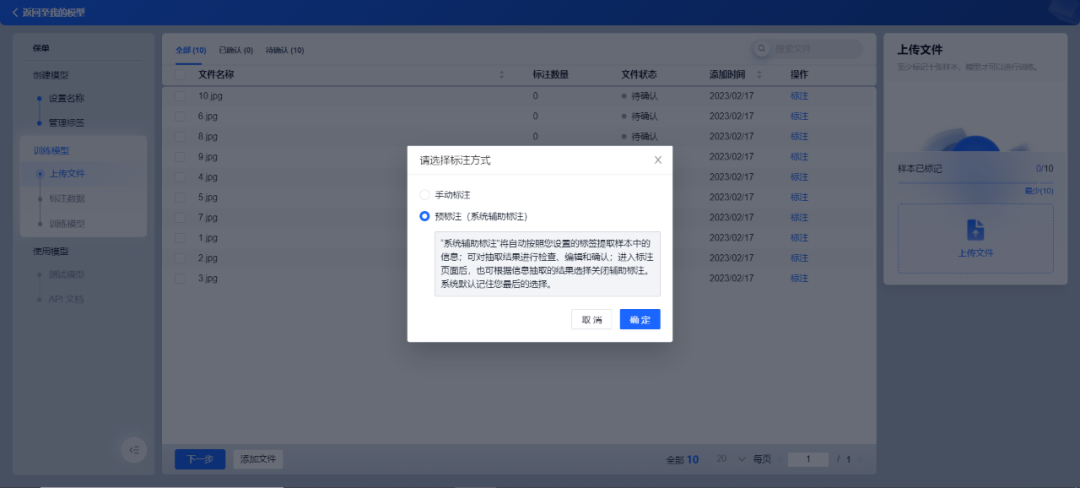
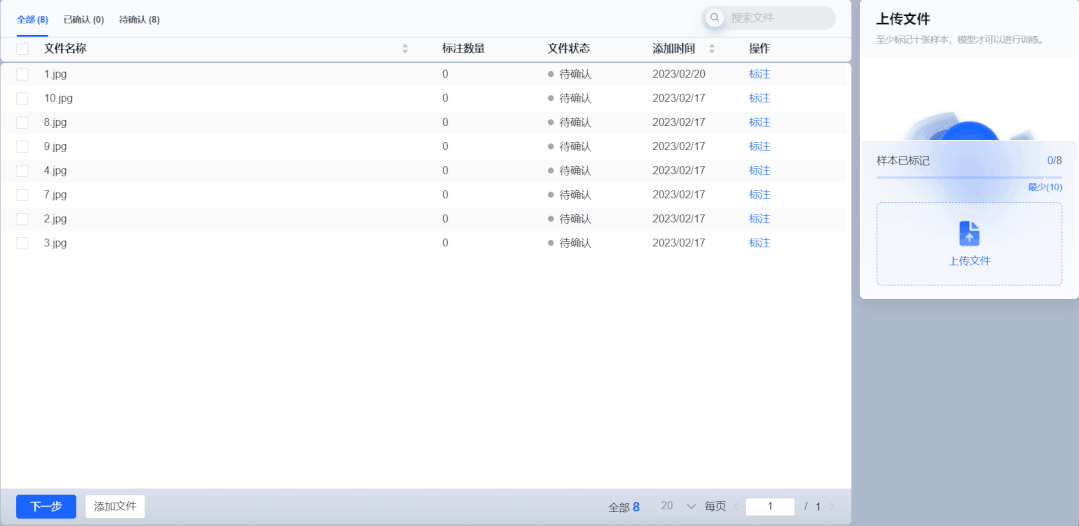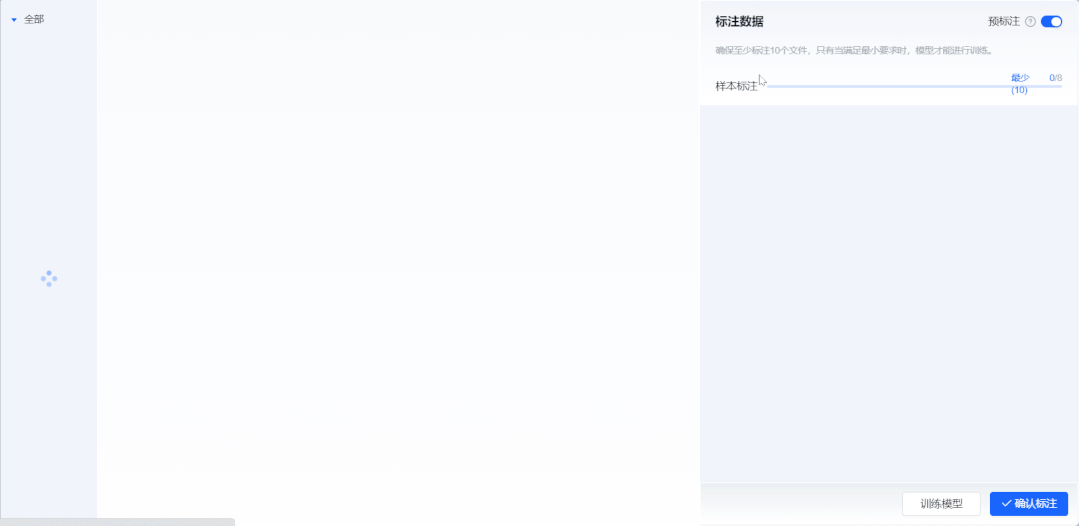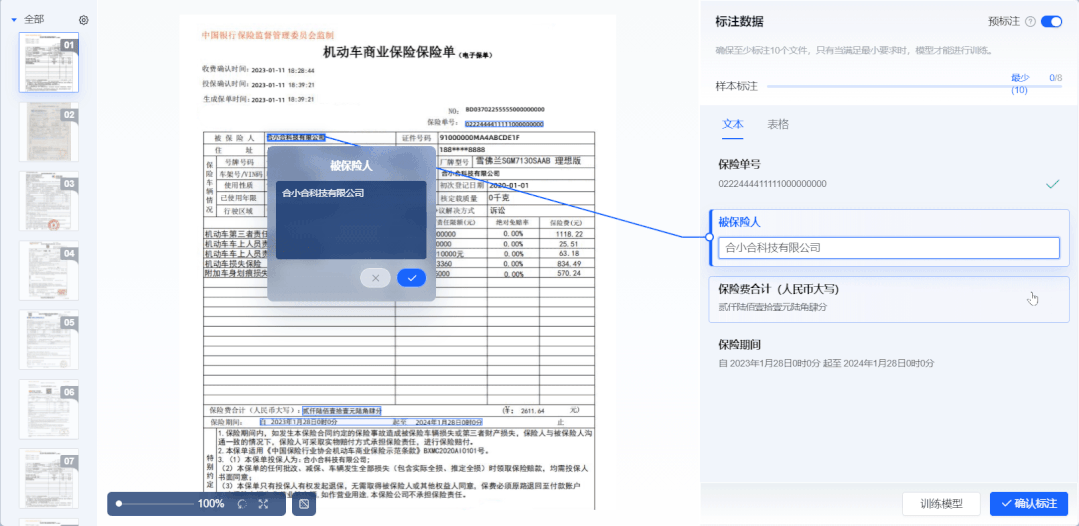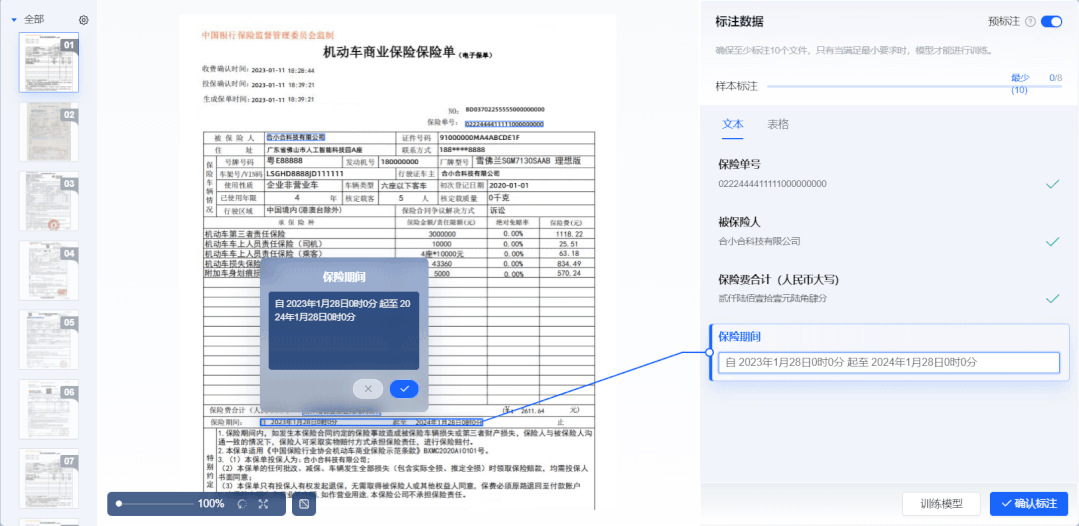
系统支持对抽取结果进行检查、编辑和确认。用户只需复核抽取结果,即可生成标注良好的可用样本。将传统的算法工程师“人工标注+人工复核”流程简化为“智能机器标注+人工复核”,极大提升了训练效率,降低了人力成本,零算法基础开发者与实际业务人员也可自主完成模型标注训练全流程。
③新增“悬浮辅助标注”,悬浮显示虚线框,无需手动框选

用户无需手动操作框选字段,只需要将鼠标悬浮至字段上方,系统自动显示虚线框,直接点击即可抽取信息,提升标注效率。
04
应用场景及行业

























